

Uit gelekte interne communicatie blijkt dat Nvidia dagelijks levenslange YouTube-video's schraapt om video-AI-model te trainen, Jensen blij met de vooruitgang

Nvidia traint zijn Omniverse, zelfrijdende auto's en "digitale menselijke" auto's op basis van gegevens van "80 jaar aan video's per dag" van YouTube en andere bronnen, zo blijkt uit een onderzoek van 404 Media.
Uit interne communicatie die door 404 Media is uitgelekt, blijkt dat Nvidia deze gegevens gebruikt om zijn AI-videowereldmodel Cosmos te trainen (niet te verwarren met de bestaande Cosmos Deep Learning-service van het bedrijf)). Cosmos is intern bedoeld als een model dat andere Nvidia-lijnen zou aandrijven, waaronder GeForce, GPU-architectuur, DGX, Deep Learning frameworks, Omniverse, Avatar, Project GR00T en autonome voertuigen.
Nvidia-leidinggevenden noemden Cosmos een state-of-the-art basismodel"dat simulatie van lichttransport, fysica en intelligentie op één plaats samenvat om verschillende downstreamtoepassingen te ontsluiten die cruciaal zijn voor Nvidia."
404 Media had toegang tot Slack-berichten van interne medewerkers waaruit bleek hoe medewerkers het commandoregelprogramma yt-dlp om YouTube-video's te downloaden met behulp van 20 tot 30 virtuele AWS-machines die IP-adressen verversen om te voorkomen dat ze door YouTube worden geblokkeerd. De site voor het delen van video's was de belangrijkste bron voor het schrapen van video's, maar werknemers overwogen ook andere bronnen zoals Netflix en Discovery Channel.
In Slack-communicatie is te zien dat werknemers de juridische gevolgen bespreken van het schrapen van auteursrechtelijk beschermde inhoud om AI te trainen, maar dat dit door projectmanagers wordt afgedaan als een beslissing van de leidinggevende, en dat is iets waar ze zich geen zorgen over hoeven te maken.
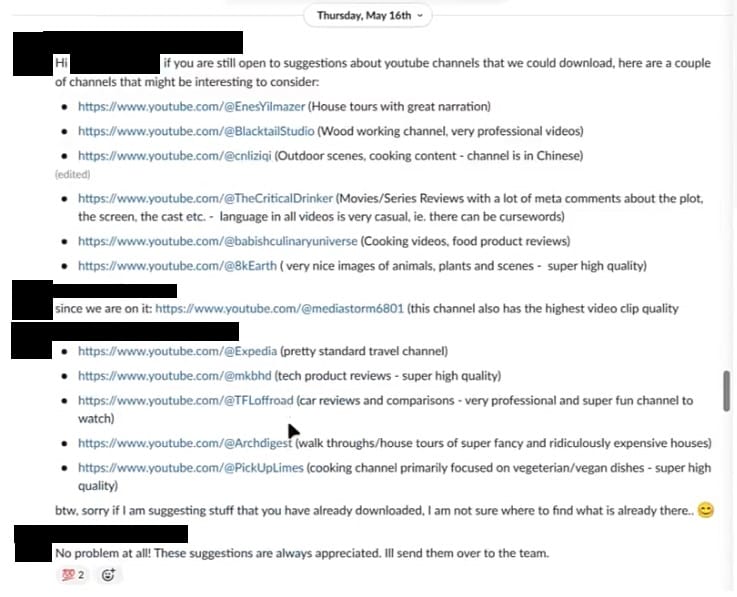
Populaire YouTube-kanalen die Nvidia-medewerkers op de shortlist hebben gezet, zijn onder andere MKBHD, PickUpLimes, Architectural Digest, Expedia, Mediastorm6801, 8kEarth en The CriticalDrinker.
Toen 404 Media contact met hen opnam, zeiden zowel YouTube als Netflix dat het schrapen van inhoud op hun platforms om AI-modellen te trainen een duidelijke schending van hun servicevoorwaarden is.
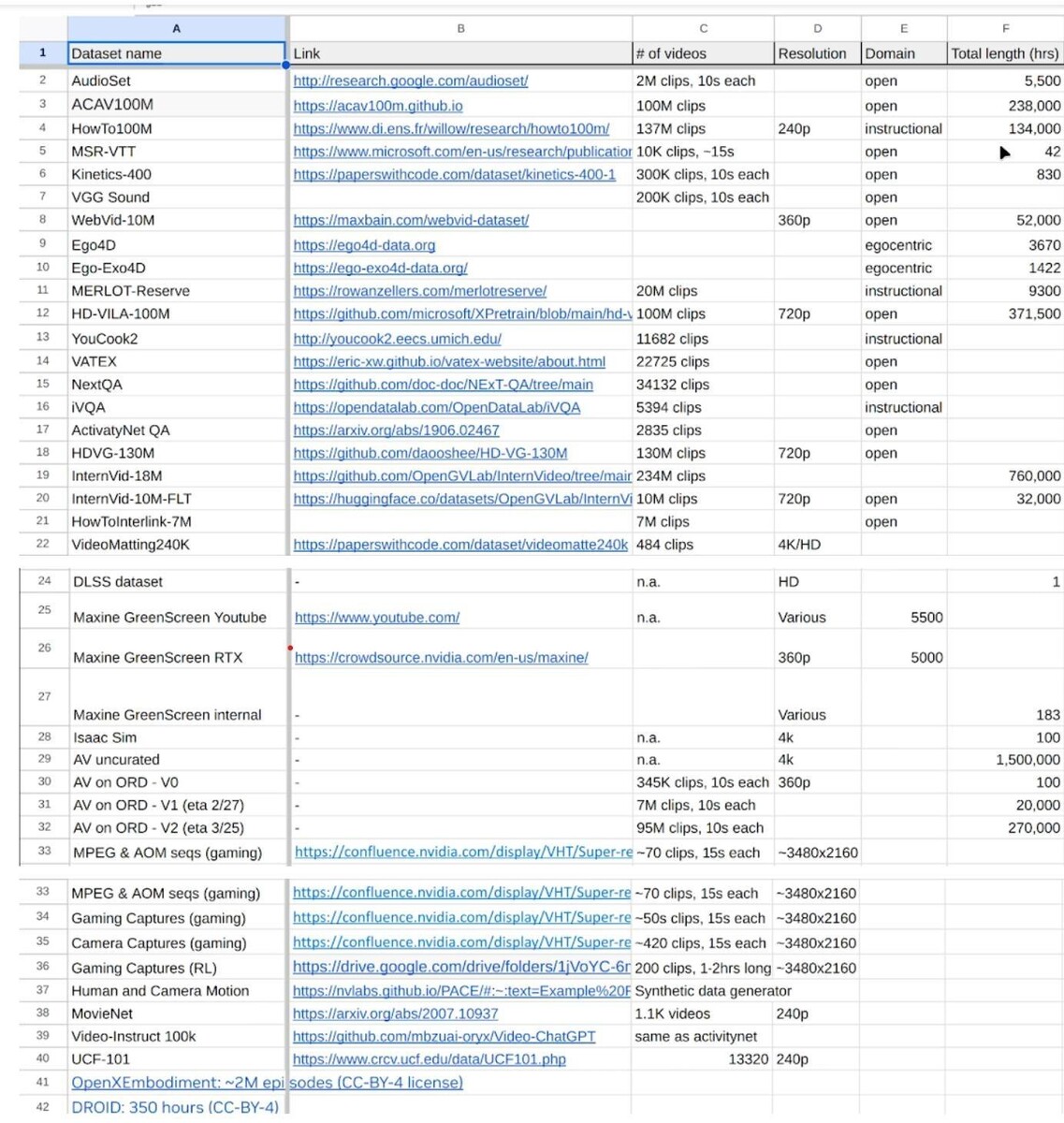
Het gebruik van auteursrechtelijk beschermde gegevens om AI-modellen te trainen is nog steeds een juridisch grijs gebied. Openbare datasets zoals InternVid-10M, HD-VG-130Men andere die gebaseerd zijn op miljoenen YouTube-video's bestaan, maar ze zijn alleen bedoeld voor academisch onderzoek en niet voor commerciële doeleinden. Hoewel Nvidia academische onderzoekers heeft, zal de output uiteindelijk zijn weg vinden naar een commercieel product.
Er zijn een paar wetten die transparantienormen voorschrijven en bedrijven die aan AI-modellen werken verplichten om samen te werken met de FTC en het Copyright Office. Maar bedrijven maken niet noodzakelijkerwijs hun brondatasets openbaar, wat het controleren een stuk moeilijker maakt.
Aangezien grote AI-bedrijven hun handen blijven leggen op alle beschikbare openbare gegevens om effectievere modellen te trainen, zijn wetswijzigingen dringend nodig om de veiligheid van de consument te garanderen en intellectueel eigendom van makers te beschermen.
Vorig jaar klaagde The New York Times OpenAI en Microsoft aan voor het ongeautoriseerde gebruik van auteursrechtelijk beschermde artikelen van de publicatie om AI-modellen te trainen. In mei spanden beeldend kunstenaars een rechtszaak aan tegen tegen Stability AI, Midjourney, DeviantArt en Runway AI voor het zonder toestemming gebruiken van kopieën van hun werk om AI-modellen te trainen.
YouTube blijkt een goudmijn aan gegevens te zijn voor AI-bedrijven. Onlangs meldde Wired https://www.wired.com/story/youtube-training-data-apple-nvidia-anthropic/ dat zwaargewichten als Apple, Nvidia, Anthropic en Salesforce ondertitels van 173.536 YouTube-video's van meer dan 48.000 kanalen hebben geschraapt om hun AI te trainen.
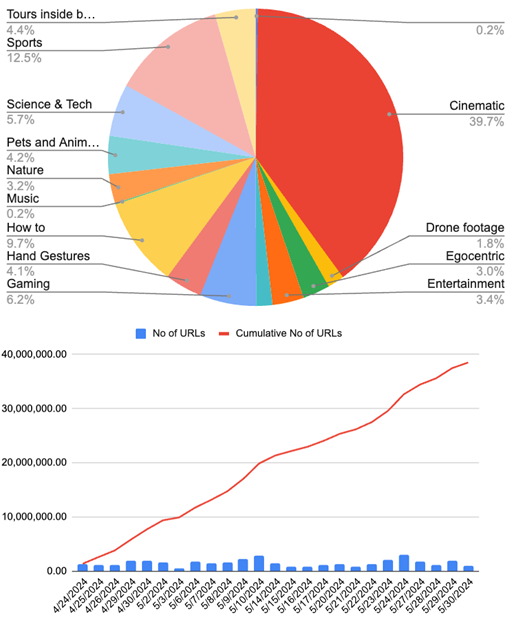
Tot eind mei kondigden medewerkers van Nvidia intern aan dat ze 38,5 miljoen video-URL's hadden verzameld, waarvan het merendeel cinematografische content betrof. De technici voegden ook datasets toe zoals Ego-Exo4D, Ego4D, HOI4Den spelgegevens van GeForce Now.
Terwijl Ego-Exo4D en Ego4D kunnen worden gelicentieerd voor zowel academisch als commercieel gebruik, wordt HOI4D gedistribueerd onder een CC BY-NC-licentie die commercieel gebruik specifiek verbiedt.
Het team traint momenteel een 1B-model met elk 16 nodes, met plannen om het op te schalen naar 10B.
Nvidia vertelde 404 Media via e-mail dat"onze modellen en onze onderzoeksinspanningen volledig in overeenstemming zijn met de letter en de geest van de auteursrechtwetgeving."
Ondertussen lijkt Nvidia CEO Jensen Huang blij te zijn met de vooruitgang die zijn personeel boekt.
Naar verluidt riep hij uit: "Geweldige update. Veel bedrijven moeten video FM [basismodellen] bouwen. Wij kunnen een volledig versnelde pijplijn aanbieden."
SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels of company despite staff legal/ethical concerns:https://t.co/DydXOyffUQ
— Jason Koebler (@jason_koebler) August 5, 2024
Bron(nen)
404 Media (Aanmelden vereist)









![Jensen Huang wilde niet fuseren tenzij hij de CEO van het gezamenlijke bedrijf zou worden (Afbeeldingsbron: Nvidia en AMD [bewerkt])](fileadmin/_processed_/2/4/csm_AMD-x-Nvidia_59a787d2dc.jpg)

