

Interview | "Onze grote cores in het midden zijn beter dan hun leger van kleine cores" AMD's Ben Conrad praat over enkele van de ontwerpbeslissingen achter Ryzen AI APU's en wat de Strix Halo zo bijzonder maakt

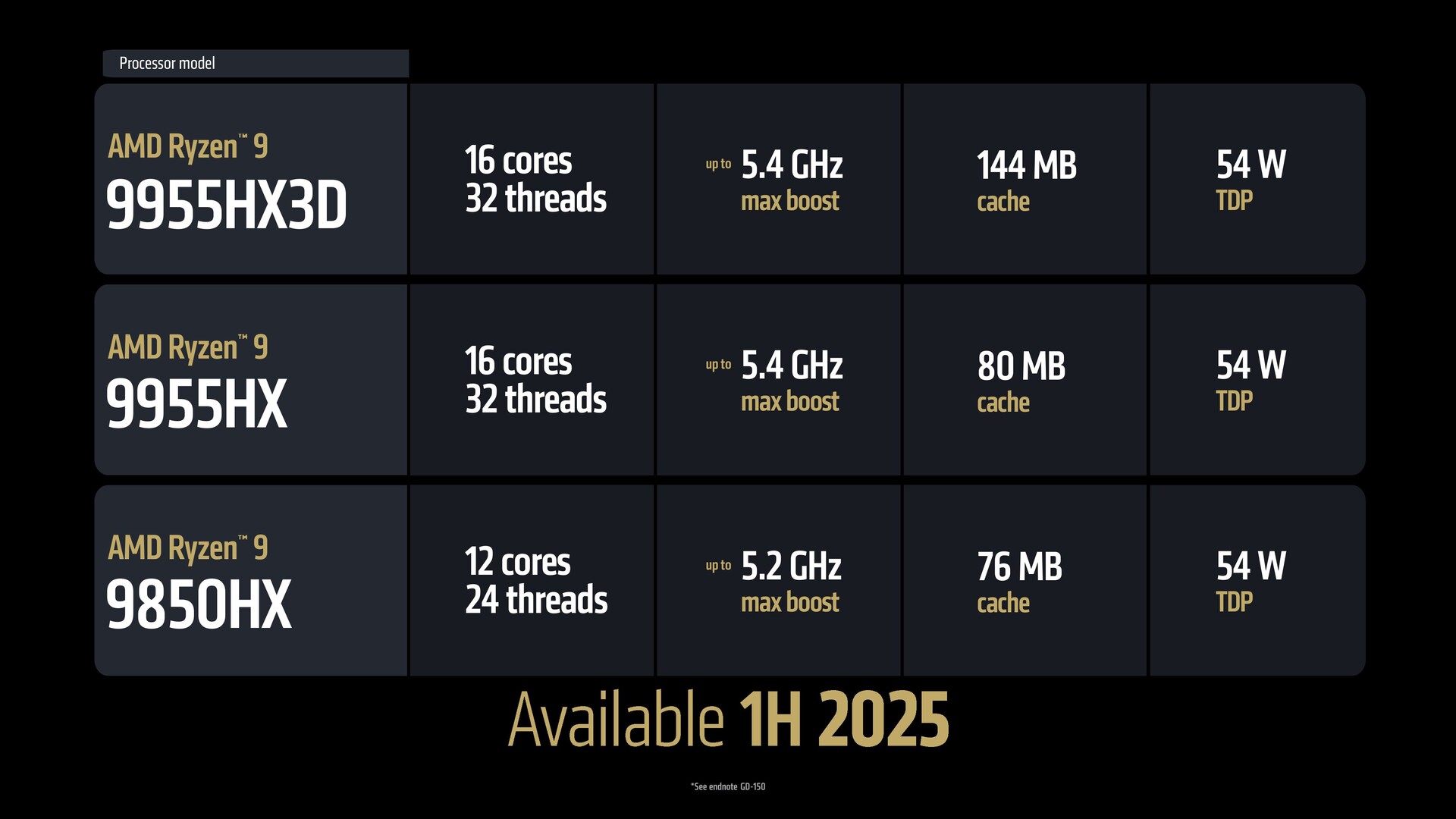
AMD had een drukke CES 2025 met een heleboel nieuwe hardware-aankondigingen. Deze omvatten de Ryzen 9 9950X3D desktop CPU, Ryzen 9 9955HX3D en andere Fire Range APU'seen voorproefje van RDNA 4, nieuwe Ryzen AI 300 en 200-serie APU's, en het vlaggenschip Ryzen AI Max Strix Halo.
Aan de zijlijn van het evenement sprak Notebookcheck's Vaidyanathan Subramaniam (VS) met AMD's Ben Conrad, Director of Product Management for Premium Mobile Client, over de nieuwe Ryzen APU lanceringen en wat deze betekenen voor AMD ten opzichte van de concurrentie, en de richting die de mobiele markt de komende dagen waarschijnlijk op zal gaan.
TL;DR: AMD straalt optimisme uit met Strix Point en Strix Halo
Hier volgt een korte samenvatting van wat we uit onze interactie met Ben hebben opgestoken. Het volledige interview volgt hieronder:
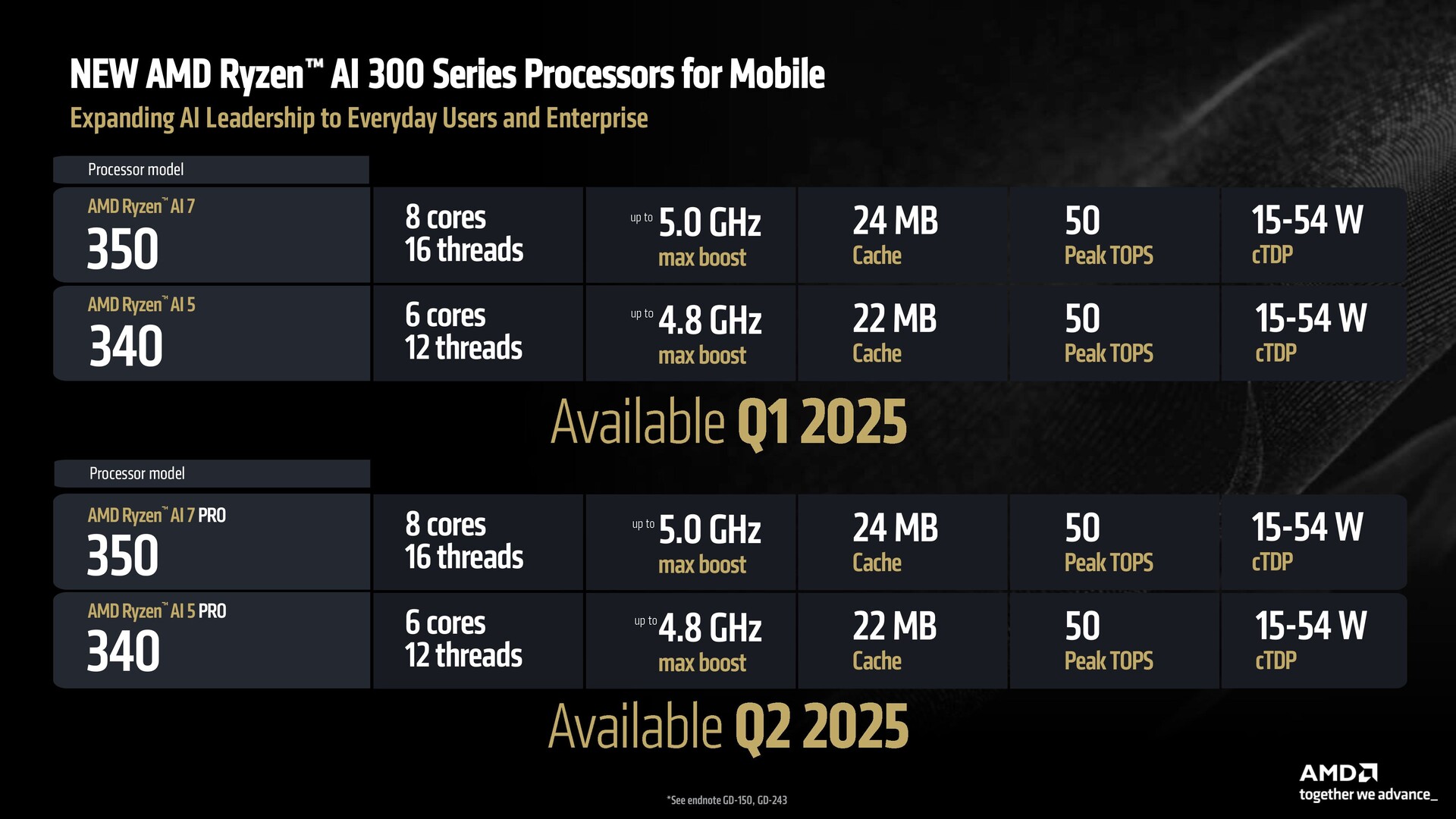
- De Ryzen AI 300-serie biedt een compleet portfolio voor gebruikers van alle vereisten.
- Alle Ryzen AI 300 Series en de Ryzen AI 200 Series zijn pakketcompatibel met eerdere lanceringen van Strix Point.
- Er zijn geen plannen om de Ryzen AI 300-serie en de Ryzen AI 200-serie naar Chromebooks te brengen.
- AMD's "big Middle" implementatie met Zen 5 en Zen 5c cores is een betere gok dan de P-core/E-core benadering van de concurrentie met weinig tot geen scheduling penalties.
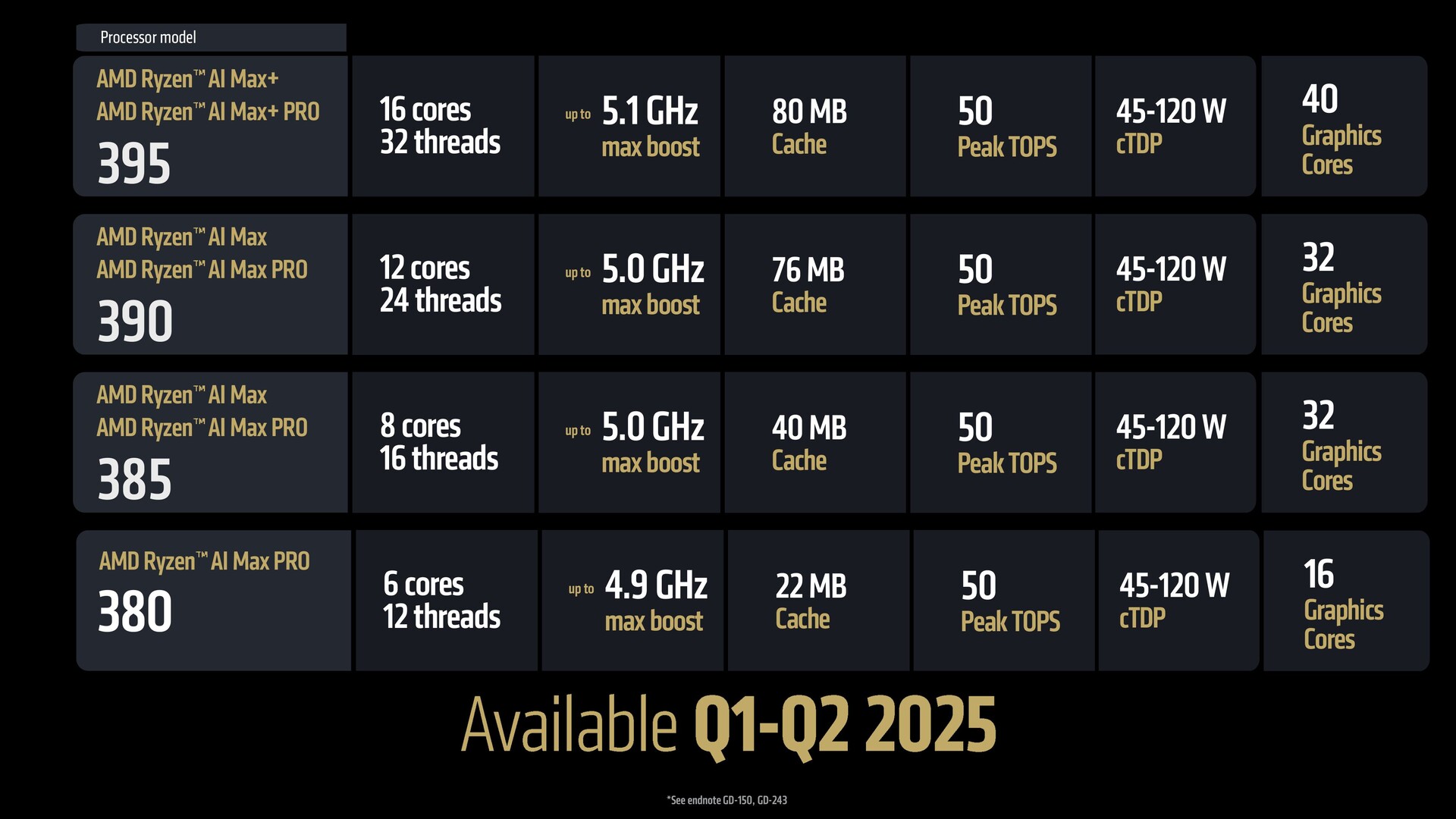
- Strix Halo Ryzen AI Max gebruikt dezelfde "klassieke" Zen 5-kernen als desktop Ryzen 9000 en Fire Range HX 3D-onderdelen.
- Strix Halo is afgeleid van de desktop en is voorzien van AVX-512, maar heeft andere interconnects die geoptimaliseerd zijn voor vermogen.
- De RDNA 3.5 van de Strix Halo biedt dezelfde geheugenbandbreedte als een RTX 4070, samen met 32 MB Infinity Cache. Bewuste beslissing om niet te kiezen voor on-package geheugen.
- Ryzen AI APU's gebruiken een beter SmartShift-algoritme dat geoptimaliseerd is voor stroombudgetten.
- De Strix Halo ondersteunt geen dGPU's en heeft slechts 12 PCIe Gen 4 lanes vanaf de CPU. Komt ook naar mini-PC's.
- Ryzen AI Max verdubbelt geheugensnelheden naar LPDDR5-8000 en biedt vergelijkbare bandbreedte als de RTX 4070.
- Momenteel geen Dragon Range Refresh gepland, maar toekomstige Fire Range Refresh niet uitgesloten.
- RDNA 4 zal alleen gericht zijn op de desktop, maar toekomstige mobiele dGPU's en APU's zijn zeker een mogelijkheid.
- Er zijn plannen om na verloop van tijd NPU-mogelijkheden naar lagere prijspunten te brengen.
Het duidelijke Ryzen AI-voordeel
VS: Bedankt voor uw tijd, Ben. Laten we beginnen met hoe AMD zichzelf ziet met de nieuwe aankondigingen, hun marktpositionering en gedachten over de concurrentie, met name in het laptopsegment.
Ben: Het algemene beeld is er een van groot potentieel. We hebben de Ryzen AI 300, die we uitbreiden naar de Ryzen AI 7 en Ryzen AI 5 SKU's. We hebben ook de Ryzen 9 9 SKU, die we uitbreiden naar de Ryzen AI 7 en Ryzen AI 5 SKU. We hebben ook de Ryzen 9 9955HX3D voor high-end gaming en werkstations (laptops). Dan hebben we ook nog de baanbrekende Ryzen AI Max voor dunne en lichte gaming en dunne en lichte werkstations - een soort best of everything-systeem.
In vergelijking met onze concurrenten is de Ryzen AI 300-serie een Zwitsers zakmes. Er zit dGPU aan vast, dus het ondersteunt dun en licht gamen. Als u waarde hecht aan de mogelijkheid om geheugen te vervangen of toe te voegen aan uw systeem, ondersteunt het DDR5-uitbreiding die de concurrentie ontbeert. Tot slot biedt het ook Copilot+ voor gamesystemen.
Al deze dingen maken het uniek. Onze concurrenten moeten meerdere producten uitbrengen om datzelfde gebied te bestrijken, terwijl wij dat allemaal kunnen met de 300 Series. En dan doen we nog coole, gekke dingen zoals de Ryzen AI Max.
Een andere input voor onze OEM-klanten in laptops is dat we een pakketcompatibiliteitsverhaal hebben. Alle modellen uit de 300-serie, inclusief de Strix Point die we in de zomer hebben gelanceerd en de Kraken Point die we nu lanceren, zijn compatibel met pakketten en kunnen in hetzelfde systeem worden aangeboden. Alle Ryzen 200-reeksen die op Hawk Point Zen 4 gebaseerd zijn, zijn ook pakketcompatibel.



Dus we geven één systeem op meerdere prijsniveaus - Copilot+ en AI met enorme grafische mogelijkheden, helemaal tot aan de N minus één product dat nog steeds geweldig is en nog steeds behoorlijk goed concurreert op de markt.
Als de koper de chassiseigenschappen van dat platform op prijs stelt en hij wil dat tegen een (lagere) prijs, dan hebben we de 200 Serie en als hij de toekomstbestendigheid van AI en alle mogelijkheden van de 300 Serie wil, dan hebben we die ook. Er is flexibiliteit.
VS: Biedt u gedistilleerde producten voor Chromebooks op basis van deze, zoals wat we hebben gezien met de Ryzen 7020C-serie?
Ben: We hebben geen plannen voor de 300 Serie in Chromebooks.
VS: Hoe zit het met de 200-serie?
Ben: Ik denk ook niet dat we plannen hebben voor de 200 (voor Chromebooks).
AMD's grote middenaanpak met Zen 5 en Zen 5c
VS: Worden de high-end SKU's geleverd met een mix van Zen 5 en Zen 5c of is het allemaal Zen 5? Wat zou het fundamentele verschil zijn tussen deze kernen?
Ben: Dat is een goede vraag. Veel van de SKU's in de 300-serie bieden een mix van Zen 5 "classic" en Zen 5 "compact". Onze concurrenten gebruiken de "army of little cores approach" in veel van hun systemen om een multi-threading benchmark te krijgen.
Je hebt dus heel veel kleine cores die misschien niet ISA-compatibel zijn, je weet wel, er kan wat vertaling zijn als je het proces tussen de cores moet verplaatsen. Laten we dit noemen wat ARM big.LITTLE noemt. Ik zou onze aanpak "big Middle" noemen. De compacte cores die we hebben, gebruiken dezelfde instructieset en leveren veel hogere prestaties dan de super, superlage cores op de andere cores.
En dus hebt u op een platform waar u beperkt vermogen hebt, een maximale boostfrequentie voor één thread. U kunt niet elke afzonderlijke core op bijna elke laptop tegelijkertijd op die maximale frequentie laten draaien. Deze compacte kernen hebben dus meestal een iets lagere maximale frequentie. Maar er is bijna geen nadeel, want als u in een één-thread scenario zit, kunt u één van de klassieke cores boosten.
Deze compacte cores bevinden zich in een veilig gebied, dus we kunnen interessante dingen doen met andere IP. Ze bieden ook een andere prestatiecurve in gevallen waarin we het proces op een core met minder vermogen willen uitvoeren, maar dat is in wezen het verhaal.
Het is geen enorme vertaling naar en daartussen, en het belangrijkste van deze (compacte cores) is dat ze bijna net zo presteren als een klassieke core bij lagere frequenties en dan, weet u, schalen ze niet naar de hogere frequenties, wat niet echt van invloed is op het systeem omdat u de één-thread schaling in de klassieke cores hebt.

Intel Thread Director vis-ȧ-vis AMD's idee
VS: Dus u zegt dat het besturingssysteem ze in wezen niet als een andere ISA ziet. Dat betekent dat in theorie in ieder geval veel van de potentiële planningsproblemen zouden moeten worden verlicht?
Ben: Het OS ziet ze wel als hetero cores, maar de straffen voor het niet perfect plannen zijn veel lager.
VS: Oké. Wat betreft het scheduling-aspect of de manier waarop u prioriteit geeft aan de thread om naar welke core te gaan, kan de gebruiker een frontend hebben om dit te regelen? Om u wat context te geven, uw concurrent heeft iets dat Thread Director heet. Hier wordt de logica bepaald door de CPU. Maar vaak hebben we gemerkt dat als een bepaald spel of een benchmark op de E-cores wordt geparkeerd, de scores naar beneden gaan, tenzij u dit handmatig kunt opheffen met tools van derden.
Heeft AMD plannen om controle te geven aan pro-gebruikers die met de threads willen spelen, in het BIOS of met Ryzen Master? Ik denk dat een basale threadcontrole altijd aanwezig zal zijn bij de processor. Maar als het een programma is zoals Discord, en ik wil het gewoon naar de Zen 5c core pushen, zou dat dan mogelijk zijn?
Ben: Onze concurrent heeft Thread Director nodig vanwege het enorme verschil tussen de cores. Dus als dat niet goed werkt, heb je een hele slechte ervaring. Er zijn zelfs spellen die detecteren hoeveel grote cores er zijn en alleen threads voor die cores spawnen, vanwege de straf om alle andere cores te omzeilen. Er zijn verschillende spellen die u daadwerkelijk een verschillend aantal threads ziet spawnen op basis van het aantal grote cores dat ze van het systeem inschatten.


Op AMD is de kans dat dit gebeurt veel kleiner. Ik geloof dat u een aantal mogelijkheden hebt om threadaffiniteit in te stellen om te helpen waar het is. Ik ben niet echt op de hoogte van alle softwarefuncties die we hebben om de aanpassingen te doen. We zullen waarschijnlijk moeten terugkeren als we een interne softwareproductmanager kunnen vinden die u het beste antwoord kan geven.
Voor de context, Intel nam een schot voor de boeg op AMD's gebrek aan een soortgelijk mechanisme terwijl het uitlegde waar Thread Director allemaal om draait.
VS: Hebben we in het portfolio dat nu is aangekondigd Zen 5c in een van de high-end SKU's? De Ryzen AI Max is geloof ik allemaal Zen 5?
Ben: Klopt, de Max is helemaal Zen 5. Het heeft ook AVX-512, dus dat is een functie op serverniveau die in de Ryzen AI Max zit met alle klassieke kernen. Dat is het maximum; we hebben gewoon alles erin gegooid wat we hadden, dus maximale prestaties, weet u, dezelfde 16 klassieke cores is wat beschikbaar is in de 9950X3D en de Fire Range 9955HX3D. Diezelfde capaciteiten zijn nu opgeschaald naar vormfactoren die deze platformen aankunnen.
VS: Is de Fire Range in wezen gewoon een desktoponderdeel dat in een laptopchip wordt gestopt of zijn er andere mobiele specifieke verbeteringen? Ik geloof dat de 9955HX3D een vermogen heeft van 140 W, terwijl de 9950X3D tot 170 W gaat?
Ben: Ja, het is hetzelfde silicium, dus u hebt gelijk. Het is de binning, er is software, er is tuning, er is een andere verpakking - dat zijn de verschillen die dat product onderscheiden, maar het gebruikt dezelfde basis die de 9950 op de desktop van stroom voorziet.
Ontwerpbeslissingen achter Strix Halo Ryzen AI Max
VS: De Fire Range laptops krijgen niet de Copilot+ branding, geloof ik, omdat er geen NPU op wordt geadverteerd? Aan de desktopkant vertelde Dr. Lisa Su, als ik het me goed herinner, tijdens de keynote dat we AVX-512 hebben, die AI-werklasten zou moeten versnellen, maar er is geen speciale NPU als zodanig op de desktop.
Ben: Zowel de desktops als de Fire Range hebben geen speciale NPU. Wij geloven absoluut dat de NPU de toekomst heeft. Ik zou verwachten dat trends bij AMD en anderen in de industrie NPU's naar deze mogelijkheden zouden brengen. Maar op dit moment hebben desktop en Fire Range een kenmerk dat ze in principe voor 100% op een dGPU zijn aangesloten. Er zit dus een enorme hoeveelheid AI in de dGPU.
We richten onze NPU eerst op UMA-platforms. Of u weet wel, platformen met een mix van laptops met beperkt vermogen. Dat was de reden, en we hebben een enorm breed scala aan NPU's, ik denk de beste van alle leveranciers.
VS: Nu ik het toch over UMA heb, denkt u dat 256 GB/s genoeg geheugenbandbreedte zou moeten zijn in vergelijking met bijvoorbeeld Apple silicium? Is die bandbreedte genoeg om de gegevens echt heen en weer te sturen tussen IP's? En als aanvulling, waarom is er geen on-package geheugen voor deze?
Ben: De Ryzen AI Max gebruikt letterlijk het dubbele van de LPDDR5-chips van de Ryzen 300-serie of onze concurrenten met een 128-bits bus. Dat zijn dus grote chips en dat pakket zou gigantisch worden. Wat we van onze klanten hebben gehoord, is dat ze graag de flexibiliteit hebben om geheugen te kopen en hun eigen beslissingen te nemen, en niet dat wij zeggen dat je twee opties hebt, je hebt dit of dat. Dat was dus een ontwerpbeslissing om het geheugen niet in de verpakking op te nemen.
Wat betreft de bandbreedte, aangezien we de breedte van de bus hebben verdubbeld, is het bij LPDDR5-8000 snelheden 256 gig per seconde. En dat is identiek aan de RTX 4070. Op de plek waar we proberen te voltooien, hebben we precies dezelfde bandbreedte, dus absoluut ja. Als we gewoon veel meer grafische voorzieningen op de APU hadden gezet en de geheugenbandbreedte niet hadden verdubbeld, zou het extreem beperkt zijn.
Dus, weet u, onze architecten kijken niet naar slechts één IP en maken het getal hier hoger. Je moet naar het hele systeem kijken en ervoor zorgen dat je de bandbreedte en het vermogen hebt. We hebben de 32 MB Infinity Cache, een soort Level 4 cache op de chip. Dat lijkt erg op de Infinity Cache in Radeon grafische kaarten.
VS: Deze Infinity Cache zit tussen de Radeon 8060S en de CCD?
Ben: Die cache zit tussen de rest van de chip en de geheugeninterface. Het is dus eigenlijk een cache op het laatste niveau, vergelijkbaar met het Infinity Cache-mechanisme op onze dGPU's, waar het zich tussen de GPU en het GDDR6-geheugen bevindt.
VS: Denkt u dat de Strix Halo ook geschikt is voor andere vormfactoren, zoals een mini PC?
Ben: Absoluut. We hebben hier (op CES) een paar desktops met een kleine vormfactor. Het verbaast me hoeveel mensen en OEM's enthousiast zijn over die kleine vormfactor.

VS: Wat voor soort interconnect is er tussen de CPU en de RDNA 3.5 GPU in de Ryzen AI Max? Hebben we iets in de trant van Infinity Fabric en SmartShift?
Ben: De interconnectie noemen we intern DDR SSP. Ik moet nog uitzoeken of die interne branding anders is dan die in de desktopchip, omdat we die interconnectie optimaliseren voor stroom. Als u de Strix Halo chip omhoog houdt, ziet u dat de CCD's heel dicht bij de I/O chip zitten. Hierdoor konden we meerdere Watts aan stroom besparen, en dat is het hele doel van de Strix Halo om echt weinig stroom te gebruiken voor hoge prestaties. Het is dus een andere interconnect, en het is niet hetzelfde CCD silicium als onze desktop chips.
Met SmartShift heeft u een APU en een dGPU als afzonderlijke chips, waarbij het vermogen tussen de twee wordt geklopt. Als het merkt dat de dGPU echt maximaal wordt benut, zegt het: laten we daar dit vermogen aan toewijzen. APU's hebben SmartShift gebruikt - onze SmartShift-technologie is gebaseerd op software en bevindt zich op het niveau van de firmware tussen deze twee chips.
Onze APU's maken effectief gebruik van smart-shift, waarbij het vermogen tussen de IP's op hardwareniveau wordt gedeeld omdat ze één pakket vormen. Onze APU's hebben altijd al, weet u, iets nog beters gehad, nog sneller kunnen denken, veel vaker per seconde kunnen beslissen waar het vermogen naartoe moet gaan.
Dus ja, we hebben dat (als SmartShift) nog niet in Ryzen AI Max gestopt, maar dat is gewoon inherent aan de hardware van een APU, dat is al gebeurd.
VS: En dit sijpelt door naar alle APU's in de stack?
Ben: Absoluut. Elke afzonderlijke APU wijst vermogen toe aan wat nodig is. Als er vraag is op zowel de dGPU als de cores, wordt er gekeken naar waar er meer vraag naar is en wordt er daar toegewezen.
VS: Wat dat betreft, kan een OEM de Ryzen AI Max gebruiken en toch een dGPU aanbieden, bijvoorbeeld een Radeon dGPU?
Ben: De Ryzen AI Max ondersteunt geen aangesloten dGPU. Omdat we al een dGPU-klasse APU hebben, is er eigenlijk geen reden. U kunt ze niet CrossFire-en, dus het heeft geen zin om ze tegelijkertijd aan te zetten. Eerlijk gezegd, waarom zou een OEM deze oplossing kopen en dan proberen er een dGPU op te schroeven, omdat u nu een soort van dezelfde vorm hebt als een bestaande gaming form factor.
VS: Hoe zou u in dat geval de PCIe-lanes van de CPU het beste kunnen gebruiken? Ik denk dat er veel lanes vrij zouden zijn, aangezien de meeste (slanke) ontwerpen nauwelijks één of twee SSD's hebben en OEM's meestal geen ruimte bieden voor opslaguitbreiding in deze chassis, zodat u niet de volledige PCIe-bandbreedte benut.
Ben: Er zit PCIe Gen 4 op deze chips. Ryzen AI Max biedt 12 lanes PCIe Gen 4, en onze typische APU's met een dGPU hebben 16 tot 20 lanes. Dus, de reden waarom we dat hebben verminderd is omdat u meestal ongeveer acht lanes gebruikt voor de dGPU. Omdat wij geen dGPU hebben, worden 20-8 dus 12. We willen wel dubbele SSD's en een paar andere I/O's kunnen ondersteunen, en ik denk dat sommige van onze werkstationklanten daar hun voordeel mee zullen doen.
VS: Dus, één mogelijkheid zou zijn dat u USB4 daarheen kunt leiden in plaats van naar de chipset?
Ben: Dat zou ik moeten controleren. Gewoonlijk is er in deze kleine vormfactor geen PCIe bridge chip of iets dergelijks. U wilt gewoon de APU gebruiken om die afmetingen te krijgen.
Productnomenclatuur en toekomstperspectieven
VS: Komen er ook nieuwe Dragon Range Refresh-chips uit?
Ben: Dat lijkt me onwaarschijnlijk. Ik denk niet dat we op dit moment iets aankondigen in de Dragon Range familie.
VS: Zou dat betekenen dat u de chips die u vorig jaar verkocht nog steeds blijft verkopen?
Ben: Zeker. Zelfs als een APU niet op onze huidige routekaart staat, als OEM's nog steeds systemen bouwen met de vorige ontwerpen, absoluut. Het is een lang verhaal om bestaande producten meerdere jaren over te verkopen. Niet zoals het ontwerpen van een nieuw systeem hiermee, maar hé, het systeem verkoopt geweldig dus het doet het goed, en dat zal zo blijven.
VS: Dat zou betekenen, hoewel het niet officieel is, dat u niet helemaal uitsluit dat we vernieuwde chips kunnen zien met een nieuwe naamgeving of iets dergelijks?
Ben: Weet u, in onze naamgeving willen we het klanten gemakkelijk maken om te beslissen. Soms kijken we naar een refresh zoals de 200 Series. Dat is grotendeels een vernieuwde productlijn. Die is niet gloednieuw. Maar de reden is dat het heel vreemd is voor een klant om een 300 Serie en een 8000 Serie te hebben en zich af te vragen... wacht 8000 is minder dan 300, dat klopt niet! Dus dat is een deel van de reden.
In de huidige generatie willen we dat het merk consistent is en gemakkelijk te begrijpen. Nu is het eigenlijk dat hele driecijferige merk, een hoger nummer is beter. Dus, 200 is Hawk, en dan, weet u, bij 300 krijgt u Strix Point en Kraken, en de Max helemaal bovenaan. Dat is een consistente merkstrategie. Ik denk dat we ook iets op dat gebied zullen doen voor de Fire Range lancering.
VS: Ik bedoel, toegegeven, het is niet altijd gemakkelijk om de hele naam van de chip in één keer uit te spreken "Ryzen.AI.9.300.Max.Plus"!
Ben: Ik denk dat een aantal van ons, weet je, nou, laat ik gewoon zeggen over in het AMD-domein hebben we zo veel producten, dus het is moeilijk. We willen dat iets consistent is, we willen dat het gedifferentieerd is, we willen dat consumenten het weten. Dus eerlijk gezegd, als een consument de winkel binnenloopt, denk ik dat hij Copilot+ ziet en 9, 7, 5, 3. Dat is waarschijnlijk... dat is genoeg. Ze kijken niet naar het exacte modelnummer.
We zijn allemaal (verwijzend naar enthousiastelingen) een soort inside baseball, toch? U wilt elk detail weten, dus ik denk dat dat een deel van de verschillen is.
VS: En ziet u vooruitzichten voor RDNA 4 laptops? Helaas is het aantal op AMD dGPU-gebaseerde laptop SKU's vrij anemisch.
Ben: Onze huidige grafische strategie is gericht op de desktopmarkt met RDNA 4. Dus ik denk dat u dat soort producten in de toekomst het eerst zult zien. RDNA 4 en toekomstige grafische technologieën zullen zeker hun weg vinden naar mobiele apparaten, of dat nu op APU's of toekomstige producten is.
VS: Dit is waarschijnlijk futuristisch, maar we hebben gehoord dat RDNA en CDNA samen zouden gaan.
Ben: Ja, dat is dus een langetermijnproject om de twee te verenigen, en ik ben daar persoonlijk erg enthousiast over omdat de ML-focus eigenlijk is waar de klantenmarkt op de lange termijn naartoe gaat. Dus als iedereen in dezelfde richting gaat, denk ik dat dat echt positief zou zijn.
VS: Oké, nog een laatste vraag, en dit is ook een van mijn ergernissen. Aan de lage kant denk ik dat er veel ruimte is omdat niet iedereen een heel high-end chip wil voor zijn behoeften. Dingen zoals basisbewerkingen in 1080p, de meeste chips kunnen dat nu al. Waarom concentreert AMD zich niet op bijvoorbeeld een Ryzen 3 omdat, weet u, u een 50 TOPS NPU over de hele stapel aanbiedt. Waarom niet hetzelfde doen aan de GPU-kant? Of misschien de NPU zelf gebruiken en ons een instapproduct geven waarmee u basisinhoud kunt maken en zo.
Of misschien zelfs nog lager. Zoals u weet, was er iets dat de Ryzen Embedded R1606Gdie we in een of twee minipc's hebben gezien.
Ben: Dus we hebben plannen om de NPU in de loop van de tijd naar betere prijspunten op de markt te brengen. Ik denk dat de industrie ook die kant op gaat. Dus we willen absoluut elke consument een Copilot+ PC, NPU-enabled AI-enabled ervaring bieden. Je hoeft alleen maar te kijken naar de economische aspecten en de prijspunten die daarmee gepaard gaan, en het is gewoon een siliciumgebied, oké, wat kunnen we erop zetten.
We kunnen bijvoorbeeld de geheugeninterface verlagen naar 64-bit. Maar wat doet dat met de rest van het systeem? Hoeveel kernen zijn een minimum voor dit soort prestaties? Ik denk dat ik in de afgelopen twee jaar zal zeggen dat de NPU geen bijzaak is geworden. Het is een van de drie van de drie-eenheden van de IP's waar we ons op moeten richten. Dus we proberen absoluut om die drie in alle segmenten op de juiste grootte te krijgen.
Bron(nen)
Eigen






