Onderzoekers van de Tsinghua Universiteit bouwen virtueel Agent Hospital voor AI-doktertraining zonder menselijke tussenkomst
Onderzoekers van de Tsinghua Universiteit aan het Intelligent Industry Research Institute (AIR) en het Department of Computer Science and Technology hebben een virtueel Agent Hospital gebouwd voor AI-doktertraining zonder menselijke tussenkomst. Ze creëerden eerst een simulatie van een volledig ziekenhuis met personeel en patiënten. AI-artsen kregen vervolgens de verantwoordelijkheid om diagnoses te stellen en duizenden virtuele patiënten te behandelen zonder menselijke tussenkomst. De artsen leerden snel van hun fouten en hun vaardigheden in het onderzoeken, diagnosticeren en behandelen namen aanzienlijk toe.
Virtuele simulaties, of simulacrums, bootsen een echte omgeving na voor een veilige en snelle training van AI. De computer hoeft niet te wachten tot er een zieke patiënt verschijnt, maar kan honderden, duizenden, zelfs miljoenen zieke patiënten programmeren om naar wens te verschijnen. De kosten van dergelijke simulaties zijn ook veel lager dan die van daadwerkelijke training.
Onderzoekers van Tsinghua waren in staat om snel virtuele AI-dokters te trainen op 10.000 virtuele patiënten in de simulatie Agent Hospital met behulp van hun proces genaamd de MedAgent-Zero methode. Deze werden gecreëerd door het voeden van grote taalmodellen met informatie over acht soorten ziekten om elektronische gezondheidsdossiers te creëren voor 10.000 virtuele patiënten, die elk een verschillende ernst en presentatie hadden. Deze acht ziekten waren acute nasofaryngitis, acute rhinitis, bronchiale astma, chronische bronchitis, COVID-19, influenza A, influenza B en mycoplasma-infectie. Een aparte set van 500 patiëntendossiers werd aangemaakt om te testen.
Tijdens de simulaties ontwikkelden de virtuele artsen met gpt-3.5-turbo-1106 snel hun vaardigheden. Na het zien van 10.000 virtuele patiënten had de arts succespercentages bij het onderzoeken, diagnosticeren en behandelen van patiënten van 88%, 95,6% en 77,6%, afhankelijk van de ziekte.
GPT wordt snel beter, dus testten de onderzoekers van Tsinghua hun MedAgent-Zero trainingsmethode ook met de krachtigere gpt-4-1106-preview. Ze vergeleken de prestaties van gpt-3 en gpt-4 AI-artsen met behulp van 1.273 vragen uit de MedQA databaseeen grote set meerkeuzevragen die lijken op medische licentievragen die te vinden zijn op testen zoals de USMLE. De prestaties van virtuele artsen op vragen over ademhalingsaandoeningen was 93,06% gpt-4 tegenover 84,72% gpt-3.
De baanbrekende prestaties van deze AI-dokters werden bereikt met slechts enkele dagen virtuele training, en het simulacrum van het Agent Hospital opent de weg naar de ontwikkeling van trainingsmethoden voor toekomstige AI-dokters, evenals voor echte artsen, die aanzienlijk sneller en effectiever zijn.
Lezers die niet weten welke banen er overblijven in een AI-aangedreven toekomst, kunnen gewoon hun 1X humanoïde robots om eten te maken en het huis schoon te maken. Mensen die AI willen bouwen, moeten hun PC uitrusten met een snelle Nvidia GPU (zoals deze op Amazon) of een van de snelste laptops ter wereld kopen(zoals deze op Amazon) om te beginnen met het trainen van AI om veel banen over te nemen.

Bron(nen)
Machine vertaald door Edge browser:
AIR creëert een virtueel ziekenhuis om de zelfevolutie van AI-artsen te realiseren
Tijd van uitgave: 2024-05-24
Het Tsinghua University's Intelligent Industry Research Institute (AIR) en het Department of Computer Science and Technology van de Tsinghua University hebben samengewerkt om een virtueel ziekenhuis te bouwen, Agent HospitalMedAgent-Zero, een zelf-evolutiemethode voor medische agenten, wordt voorgesteld, die medische agenten in staat stelt om hun medische capaciteiten voortdurend te verbeteren door een grote hoeveelheid gegevens te genereren zonder handmatige annotatie in virtuele ziekenhuizen, en wordt geverifieerd in echte datasets. Alle patiënten, verpleegkundigen en artsen in het Agent Hospital worden gespeeld door autonome agents die worden aangestuurd door grote modellen, die het gesloten-lus proces van "pre-hospital-in-hospital-post-hospital" van begin, triage, registratie, consultatie, onderzoek, diagnose, medicatie, revalidatie en follow-up simuleren. Op basis van de kennisbasis en het basismodel simuleert Agent Hospital het ziektegeneratie- en ontwikkelingsproces van virtuele patiënten. Virtuele artsen leren (d.w.z. lezen medische literatuur) en oefenen (d.w.z. interageren met virtuele patiënten en maken diagnose- en behandelingsbeslissingen) in Agent Hospital, vatten voortdurend ervaringen samen uit succesvolle diagnose- en behandelingsgevallen, denken na over lessen uit mislukte gevallen en verbeteren voortdurend de nauwkeurigheid van meerdere diagnose- en behandeltaken. Na het behandelen van bijna 10.000 virtuele patiënten (menselijke artsen doen er ongeveer 2 jaar over), waren virtuele artsen in staat om de huidige beste methoden te overtreffen op de subset van ademhalingsaandoeningen van de MedQA dataset, met een nauwkeurigheid van 93,06%. Het onderzoek, dat mede werd geschreven door Assistant Prof. Ma Weizhi van AIR en Prof. Yang Liu, Executive Dean van AIR en Associate Dean van het Department of Computer Science, heeft na publicatie op arXiv veel aandacht en discussie gekregen van de kunstmatige intelligentiegemeenschap en de medische gemeenschap in binnen- en buitenland.
- Titel van de paper: Agent Ziekenhuis: Een simulacrum van een ziekenhuis met evolueerbare medische agenten
- Link naar de paper: arxiv.org/pdf/2405.02957v1
In de afgelopen jaren hebben grootschalige taalmodellen zich sterk ontwikkeld, en agenttechnologie gebaseerd op grote taalmodellen heeft veel aandacht getrokken. Eerdere studies hebben agenttechnologie gebruikt om real-world simulatie te bereiken, inclusief interactie en spelscenario's zoals "Stanford Town" en "Werewolf Killing Game". Tegelijkertijd wordt agenttechnologie ook gebruikt in het plannings- en samenwerkingsproces van verschillende taken, maar dit proces is meestal afhankelijk van de ondersteuning van handmatig geannoteerde gegevens van hoge kwaliteit. Daarom is de onderzoeksvraag of real-world simulatie kan helpen om de taakverwerkingscapaciteit van agenten te verbeteren.
Slimme gezondheidszorg heeft veel aandacht getrokken vanwege het belang en de toepassingswaarde, en het onderzoeksteam heeft veel aandacht besteed aan de toepassing van grote taalmodellen en agenttechnologie in medische scenario's. Als antwoord op de bovenstaande onderzoeksvragen gelooft het team dat de echte modelomgeving de taakbekwaamheid van agenten kan helpen verbeteren en evolueren, dus voerden ze het Agent Hospital-onderzoek uit dat simulatie in de echte wereld en verbetering van medische bekwaamheid combineert. In dit werk legt het team zich toe op het bouwen van een ziekenhuissimulatieomgeving en het onderzoeken van de autonome evolutie van medische agenten in deze omgeving. Het doel is om agenten in staat te stellen zelfstandig medische kennis op te doen tijdens het proces van diagnose, behandeling en leren, net als menselijke artsen, en de voortdurende evolutie van medische vaardigheden te realiseren.
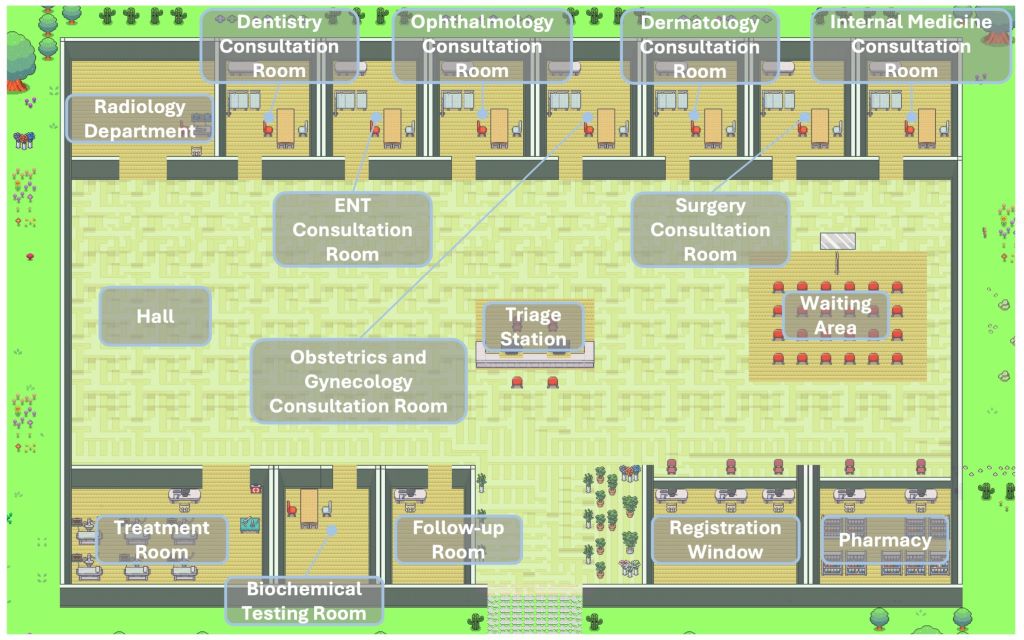
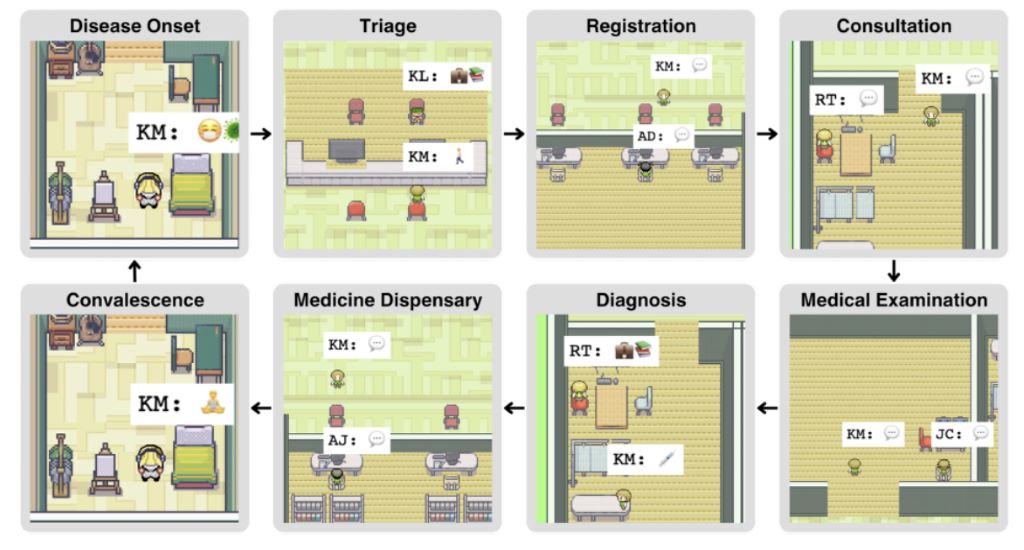
Het onderzoeksteam richtte zich eerst op het gebruik van grootschalige modelagenten om kritieke medische processen in de echte wereld te simuleren. In Agent Hospital ontwierp en behandelde het team 8 typische scenario's van het ontstaan van ziekte tot herstel, namelijk: begin, triage, registratie, consultatie, onderzoek, diagnose, voorschrijven en herstel, en patiënten zullen actief deelnemen aan follow-up feedback. Alle processen worden ondersteund door grote modellen waarin de rollen autonoom kunnen samenwerken.
Voorbeelden van grote diagnose- en behandelsessies
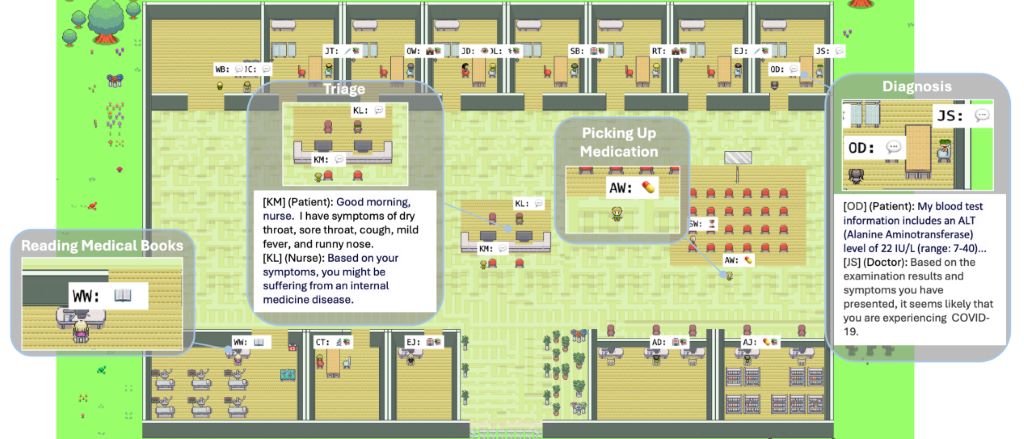
Het bovenstaande diagram illustreert een gesloten-lus benadering: wanneer Kenneth Morgan, de agent van de patiënt, ziek wordt, gaat hij naar het ziekenhuis voor hulp. Triageverpleegkundige Katherine Li begrijpt de symptomen van Morgan, analyseert hem en triageert hem naar een specifieke afdeling. Nadat Morgan de registratie, het consult en het medisch onderzoek volgens de instructies van de arts heeft voltooid, zal dokter Robert hem de definitieve diagnose en het behandelplan geven, en Morgan zal naar huis gaan om te rusten volgens de instructies van de arts en feedback geven aan het ziekenhuis voor herstel, tot de volgende keer dat hij ziek wordt en dan naar het ziekenhuis gaat.
Zoals u in het bovenstaande voorbeeld kunt zien, ontwierp het onderzoeksteam twee hoofdtypen rollen voor het ziekenhuis: medisch personeel en patiënten. Alle informatie over de personages is gegenereerd door een groot model (GPT-3.5), zodat het gemakkelijk geschaald en toegevoegd kan worden. De specifieke informatie van sommige personages wordt in de onderstaande afbeelding getoond: de 35-jarige patiënt Kenneth Morgan heeft momenteel acute rhinitis, een voorgeschiedenis van hoge bloeddruk en een reeks symptomen zoals aanhoudend braken; Zhao Lei is een ervaren radioloog, en internist Elise Martin heeft uitstekende communicatieve vaardigheden en is gespecialiseerd in de diagnose en behandeling van acute en chronische medische ziekten. Deze complete personage-informatieachtergronden versterken het realisme van de ziekenhuissimulatie.
Een inleiding tot de informatie van het virtuele personage
In het bovengenoemde medische simulatieproces staat het genereren van ziekte centraal. De huidige medische dossierinformatie wordt gegenereerd door een groot taalmodel in combinatie met medische kennis om een compleet medisch dossier voor de patiënt te genereren, inclusief het type ziekte, de symptomen, de duur en verschillende onderzoeksresultaten (zie de bijlage van het artikel voor meer informatie). Er moet worden opgemerkt dat, om de nauwkeurigheid van het hele simulatieproces zo veel mogelijk te garanderen, de patiënt-agent alleen de symptomen van zijn ziekte zal waarnemen, maar niet de specifieke ziekte, terwijl de arts-agent alleen de informatie kan begrijpen door met de patiënt-agent te praten en tests voor te schrijven. Het onderzoek dat de patiëntagent moet uitvoeren, het soort ziekte en de ernst van de ziekte zullen worden gebruikt als drie sleuteltaken om het vermogen van de medische agent om virtuele patiënten te diagnosticeren en te behandelen, te evalueren.
De meeste traditionele trainingsmethoden voor medische modellen zijn gebaseerd op pre-training, fine-tuning en andere technologieën, dus ze moeten ondersteund worden door een grote hoeveelheid medische gegevens en handmatig geannoteerde gegevens van hoge kwaliteit. Het onderzoeksteam is echter van mening dat het proces van het verbeteren van de capaciteit van menselijke artsen niet afhankelijk is van zulke grote hoeveelheden gegevens, en dat zij vaak ervaring kunnen opdoen uit de klinische praktijk tijdens het diagnose- en behandelingsproces, en ook beter worden door het lezen van medische literatuur om belangrijke kennis op te doen. Medische agenten in virtuele ziekenhuizen zouden in staat moeten zijn om een vergelijkbare vaardigheidsevolutie te bereiken.
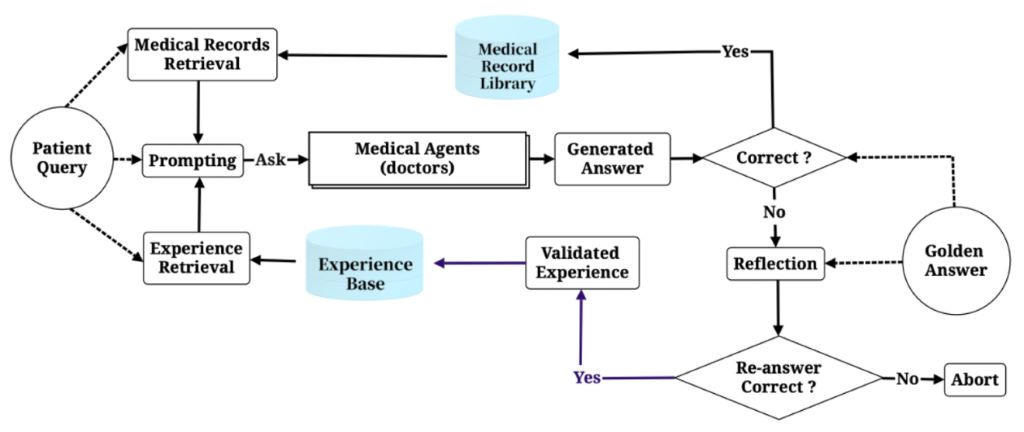
Daarom ontwierp het team een agent algoritme voor zelfevolutie genaamd "MedAgent-Zero", dat net als AlphaGo-Zero niet afhankelijk is van handmatige annotatiegegevens, maar gebruik maakt van leren (d.w.z. het lezen van medische literatuur) en oefenen (d.w.z. interactie met virtuele patiënten en het nemen van diagnose- en behandelingsbeslissingen) in het virtuele ziekenhuis om capaciteitsverbetering te bereiken. Zelfstandig ervaring opdoen met de drie taken van ziektediagnose en behandelingsaanbevelingen; Aan de andere kant zullen medische agenten ook autonoom leren, waarbij ze het leerproces van medische documenten simuleren op basis van de medische vragen die door het LLM worden gegenereerd.
MedAgent-Zero stroomdiagram
Zoals de bovenstaande figuur laat zien, omvat de evolutie van MedAgent-Zero twee benaderingen: 1) Het samenvatten van ervaring uit succesvolle gevallen, voor diagnose- en behandelingsproblemen die correct beantwoord kunnen worden, zal het intelligente orgaan ervaring uit de casusdatabase verzamelen zoals een menselijke arts; 2) Het reflecteren op lessen die geleerd zijn uit mislukkingen, en bij het beantwoorden van fouten, zal de agent het initiatief nemen om na te denken over de fouten en erover na te denken. Als de lessen uit reflectie de agent helpen bij het beantwoorden van de vraag, zal dit bewaard en opgeslagen worden in de ervaringspool.
Uiteindelijk zal het onderzoeksteam de accumulatie en evolutie van de bovenstaande twee aspecten uitvoeren in het trainingsproces op virtuele gegevens. In elk inferentieproces haalt de agent de meest gelijkende inhoud uit de twee databases en voegt deze toe aan de prompt voor leren in de context, en verzamelt medische gegevens of vat ervaringen samen op basis van de juiste en onjuiste antwoorden, zodat de vaardigheden van de agent voortdurend worden verbeterd.
In het virtuele ziekenhuis stelde het onderzoeksteam de medische dossiers samen van tienduizenden virtuele patiënten voor de autonome evolutie-experimenten van medische agenten, waaronder 8 ademhalingsgerelateerde ziekten zoals influenza A, influenza B en nieuwe kroon, waarbij meer dan 10 verschillende medische onderzoeken betrokken waren. Op basis van de berekening dat menselijke artsen ongeveer 100 patiënten per week behandelen, kunnen menselijke artsen er twee jaar over doen om 10.000 patiënten te diagnosticeren, maar intelligente artsen hebben slechts een paar dagen nodig om dit te doen.
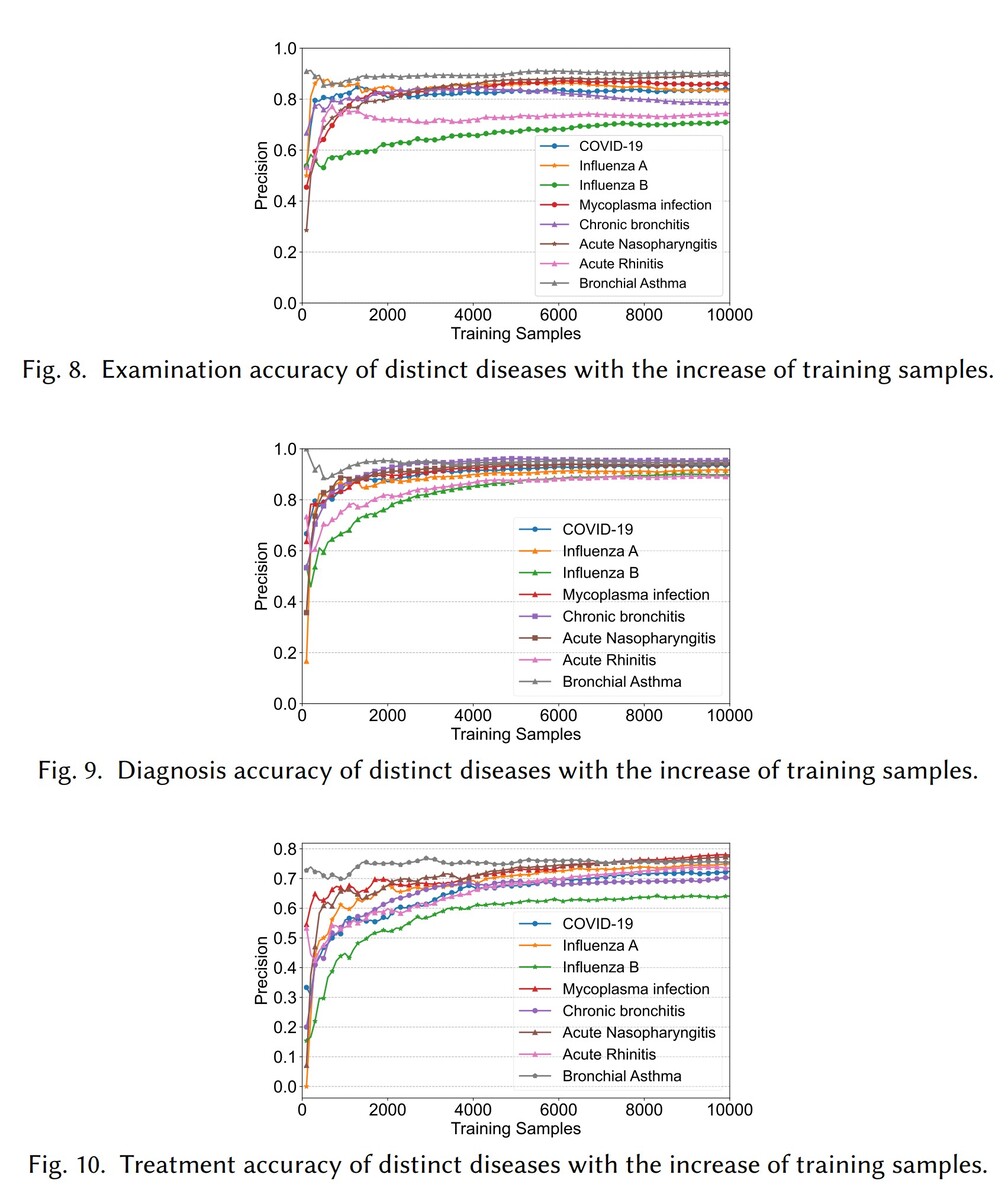
Het team evalueerde het vermogen van medische agenten in virtuele ziekenhuizen voornamelijk vanuit twee aspecten. Het eerste is de evaluatie van medische bekwaamheid in de virtuele omgeving: zoals in de onderstaande afbeelding te zien is, blijft in het trainingsproces van de medische agent (links), met de toename van het aantal gediagnosticeerde en behandelde patiënten, de nauwkeurigheid van de medische agent op de drie belangrijkste taken toenemen en stabiliseert zich geleidelijk. In het experiment met 500 medische testgegevens werd vastgesteld (rechts) dat de nauwkeurigheid van de agent licht fluctueerde naarmate het aantal patiënten toenam, maar een algemene opwaartse trend vertoonde.
De taaknauwkeurigheid van de medische agent op de trainingsset (links) en de testset (rechts).
Vervolgens vergeleek het onderzoeksteam de diagnostische nauwkeurigheid van medische agenten op verschillende ziekten voor en na hun evolutie, en ontdekte dat ze allemaal sterk verbeterd waren, waarmee de effectiviteit van hun autonome evolutie werd geverifieerd.
Diagnostische manifestaties van verschillende ziekten voor en na de evolutie van agenten
Anderzijds gebruikte het team een subset van ademhalingsziekten uit de externe dataset MedQA om het vermogen van de medische agent in de echte geneeskunde te evalueren. Verrassend genoeg was de medische agent, zelfs zonder gebruik te maken van kunstmatig geannoteerde gegevens in het evolutieproces van de agent, na het behandelen van bijna 10.000 patiënten in staat om de huidige beste methode op de dataset te overtreffen en het hoogste nauwkeurigheidspercentage van 93,06% te behalen, wat de effectiviteit van de autonome evolutie van medische agenten in de gesimuleerde omgeving verifieert.
Nauwkeurigheid van verschillende methoden op een subset van MedQA
Daarnaast voerde het onderzoeksteam experimentele ablatieverificatie uit, en de resultaten toonden aan dat zowel de voorbeelden uit de successen als de lessen uit de mislukkingen kunnen helpen om de medische capaciteiten van het model te verbeteren.
Prestaties van de ablatietest van MedAgent-Zero
Samenvattend kan worden gezegd dat dit onderzoekswerk het eerste virtuele ziekenhuisscenario, Agent Hospital, heeft geconstrueerd en MedAgent-Zero heeft voorgesteld, een evolutiealgoritme voor medische agenten dat niet afhankelijk is van kunstmatige gegevensannotatie. De experimentele resultaten van virtuele gegevens en echte gegevens verifiëren vooraf de effectiviteit van de simulatieomgeving voor de verbetering van de capaciteiten van medische agenten en stellen nieuwe oplossingen voor voor de toepassing van kunstmatige intelligentie, met name grote taalmodellen en agenttechnologie in slimme medische scenario's. Er zijn echter nog enkele beperkingen voor de toepassing van kunstmatige intelligentie. Er zijn echter nog enkele beperkingen in dit onderzoekswerk en in de toekomst zal het team doorgaan met het verbeteren en optimaliseren van de behandelde ziektetypen, de zorgvuldigheid van de simulatieomgeving en de selectie en optimalisatie van de modelbasis.
Over de corresponderende auteur
Ma Weizhi, een assistent-onderzoeker aan het Institute of Intelligent Industry (AIR) van de Tsinghua Universiteit, werd geselecteerd als het "Young Talent Lifting Project" van de China Association for Science and Technology. Zijn onderzoeksinteresses omvatten intelligente informatieverwerving en intelligente medische zorg. Persoonlijke homepage: mawz12.github.io.
Liu Yang is professor GDS, uitvoerend decaan van het Instituut voor Intelligente Industrie (AIR), plaatsvervangend decaan van het Departement Computerwetenschappen van de Tsinghua Universiteit en winnaar van het Nationaal Fonds voor Distinguished Young Scholars. Zijn onderzoeksinteresses omvatten kunstmatige intelligentie, natuurlijke taalverwerking en slimme geneeskunde. Persoonlijke homepage: nlp.csai.tsinghua.edu.cn/~ly.

