

Meta onthult grootste, slimste, royalty-vrije Llama 3.1 405B AI

Meta heeft zijn Llama 3.1 405B AI onthuld voor royalty-vrij gebruik. Het 750 GB, 405 miljard-parameter grote taalmodel (LLM) is een van de grootste ooit uitgebracht, waardoor het met zijn uitgebreide 128K token-invoervenster kan concurreren met AI-vlaggenschepen zoals Anthropic Claude 3.5 Sonnet en OpenAI GPT-4o. In tegenstelling tot betaalde, closed-source concurrenten, kunnen lezers de gratis LLM aanpassen en uitvoeren op hun eigen computers met extreem krachtige Nvidia grafische kaarten (GPU's).
Creatie en energie
Meta gebruikt tot 16.384 700W TDP H100 GPU's op zijn Meta Grand Teton AI-serverplatform om de 3,8 x 10^25 FLOP's te produceren die nodig waren om een model met 405 miljard parameters te maken op 16,55 biljoen tokens (1000 tokens is ongeveer 750 woorden). GPU-gerelateerde storingen veroorzaakten 57,3% van de downtime tijdens de pre-training, waarvan 30,1% te wijten was aan defecte GPU's.
Er werden meer dan 54 dagen besteed aan het voortrainen van de AI op documenten, met een totaal van 39,3 miljoen GPU-uren die gebruikt werden om Llama 3.1 405B te trainen. Volgens een snelle schatting bedroeg het elektriciteitsverbruik tijdens de training meer dan 11 GWh, waarbij 11.390 ton CO2-equivalente broeikasgassen vrijkwamen.
Veiligheid en prestaties
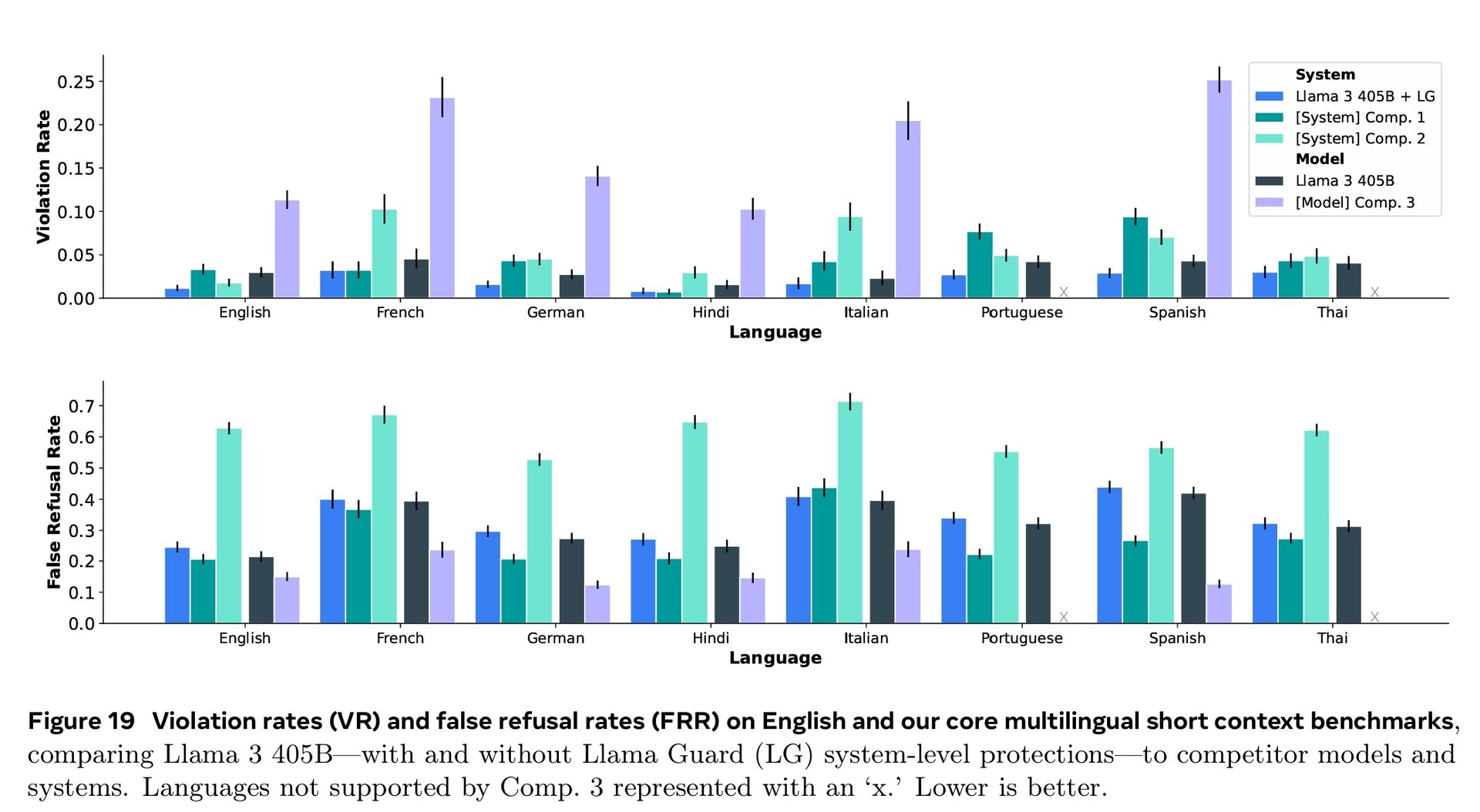
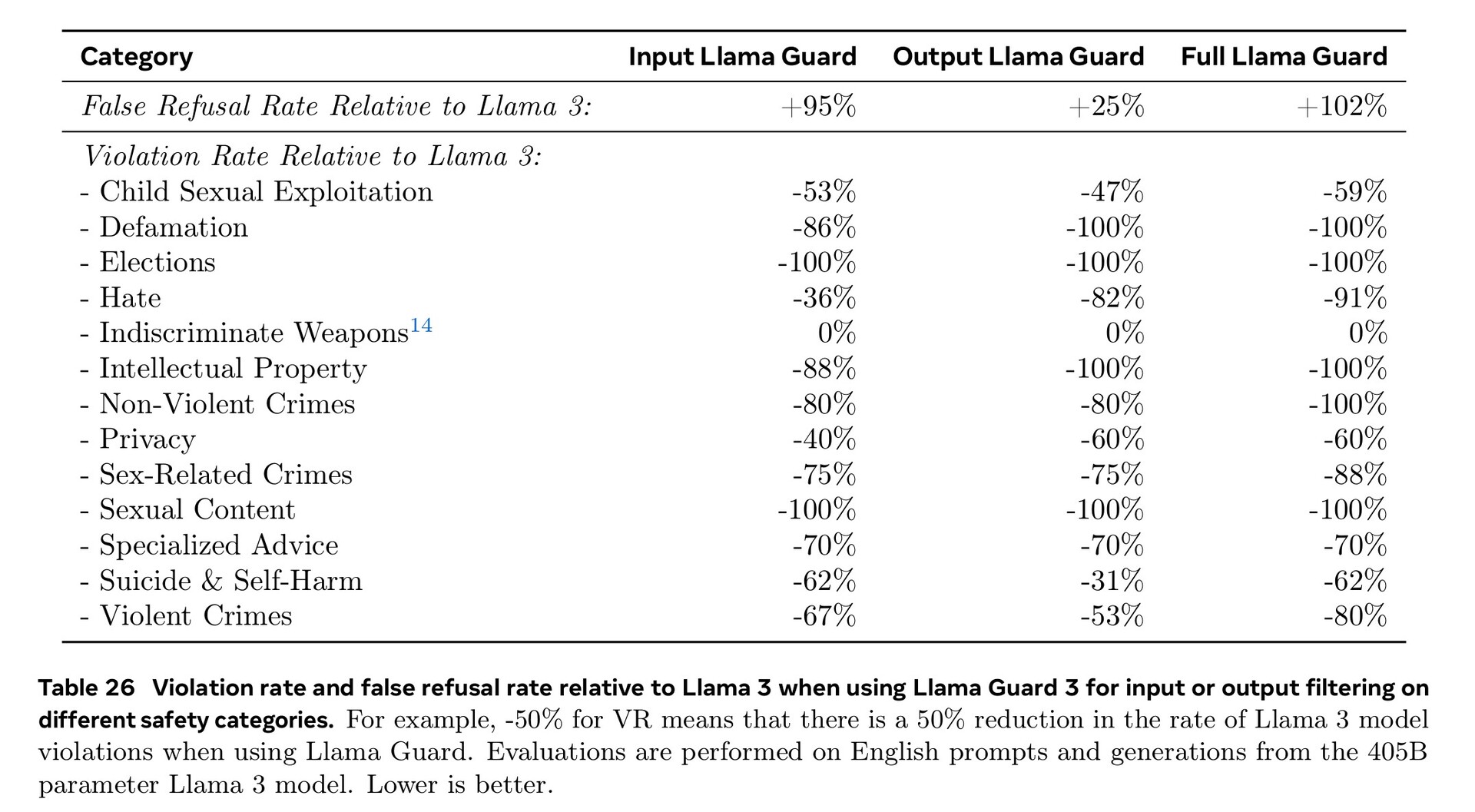
Uitgebreide training op het gebied van cyberbeveiliging, veiligheid van kinderen, chemische en biologische aanvallen, prompt injectie en meer, samen met het filteren van invoer- en uitvoertekst met behulp van Llama Guard 3, heeft geresulteerd in betere veiligheidsprestaties dan concurrerende AI-modellen. Toch betekent het kleinere aantal documenten in vreemde talen dat Llama 3.1 eerder gevaarlijke vragen in het Portugees of Frans beantwoordt dan in het Engels.
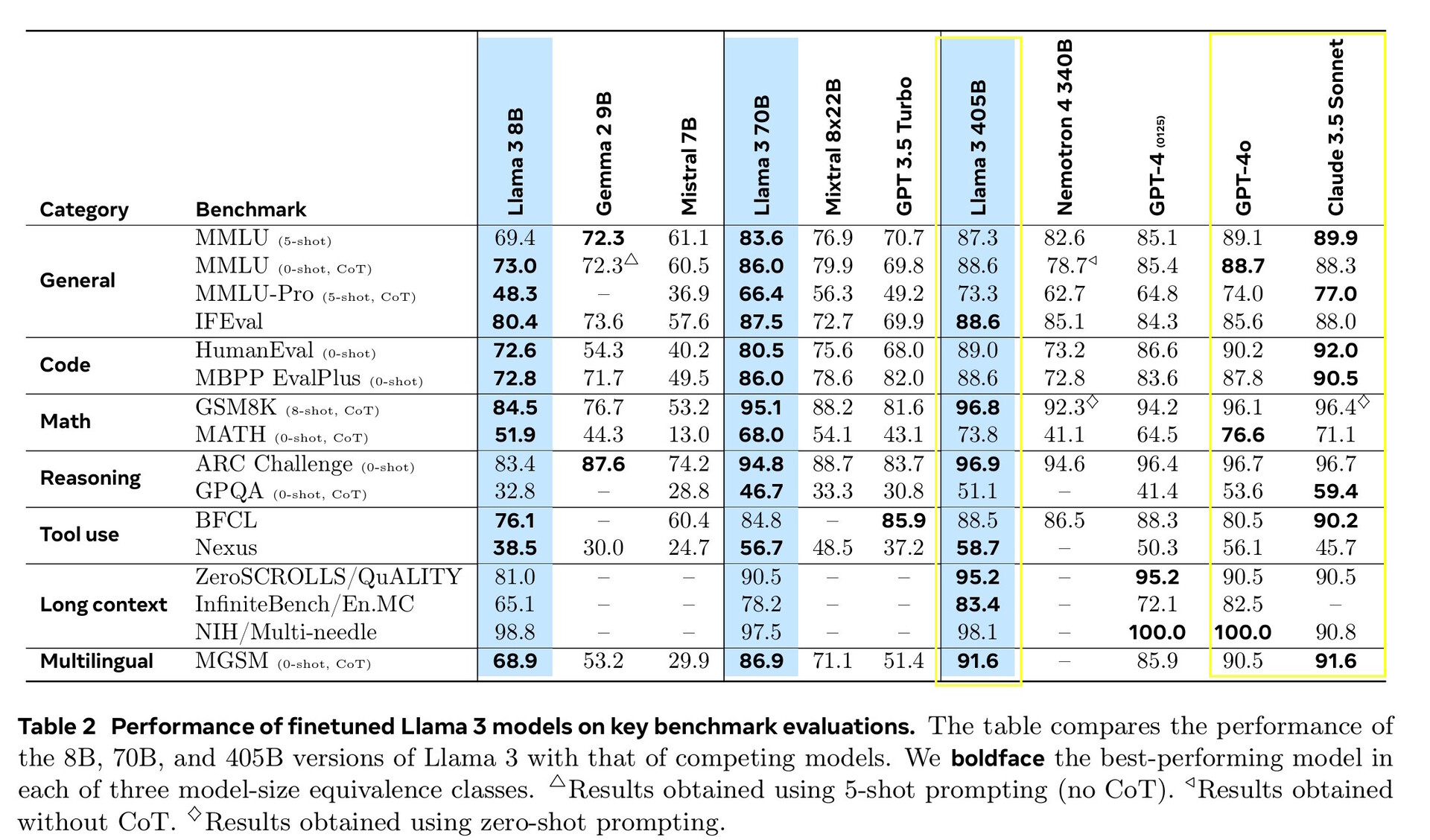
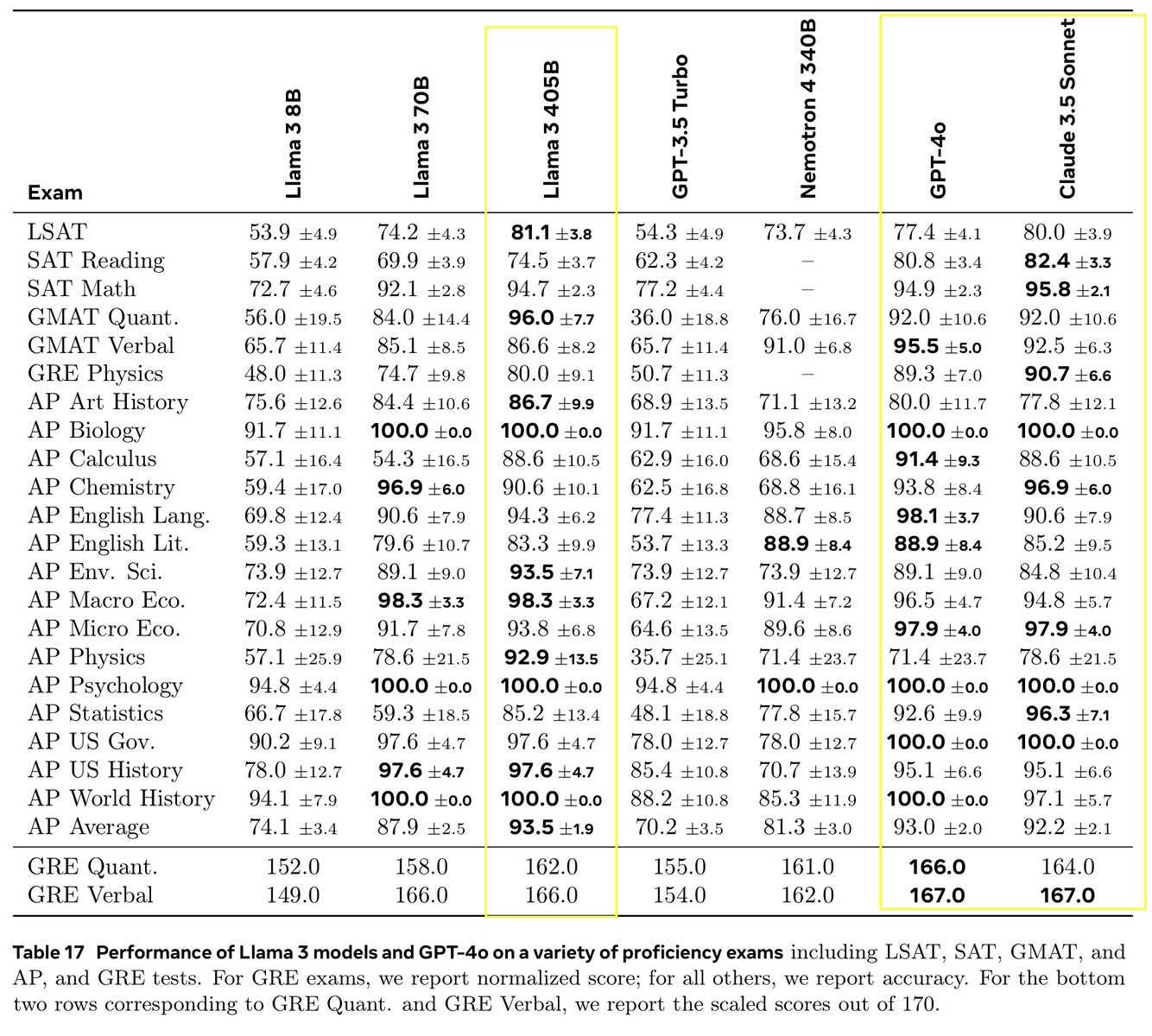
Llama 3.1 405B scoorde 51,1 tot 96,6% op AI-tests op universitair en graduaatniveau, in lijn met Claude 3.5 Sonnet en GPT-4o. In echte tests die door mensen werden beoordeeld, gaf GPT-4o 52,9% vaker betere antwoorden dan Llama. Het model weet niets verder dan de kennisafsluitingsdatum van december 2023, maar het kan de meest recente informatie online verzamelen met Brave Searchwiskunde oplossen met Wolfram Alphaen codeerproblemen oplossen in een Python-interpreter.
Vereisten
Onderzoekers die Llama 3.1 405B lokaal willen uitvoeren, hebben zeer krachtige computers met 750 GB vrije opslagruimte nodig. Voor het draaien van het volledige model zijn acht Nvidia A100 GPU's of vergelijkbaar, met twee nodes van MP16 en 810 GB GPU VRAM voor inferentie, in een systeem met 1 TB RAM. Meta heeft kleinere versies uitgebracht die minder vereisen, maar slechter presteren: Llama 3.1 8B en 70B. Llama 3.1 8B heeft slechts 16 GB GPU VRAM nodig, dus het draait prima op een goed uitgeruste Nvidia 4090 systeem(zoals deze laptop op Amazon) ongeveer op het niveau van GPT-3.5 Turbo. Lezers die gewoon een top-AI willen gebruiken, kunnen een app installeren zoals Anthropic's Android of iOS-app.
Bron(nen)
Groot Taalmodel
Maak kennis met Llama 3.1: Onze meest capabele modellen tot nu toe
23 juli 2024
15 minuten lezen
Opmerkingen:
Meta zet zich in voor open toegankelijke AI. Lees de brief van Mark Zuckerberg waarin hij uitlegt waarom open source goed is voor ontwikkelaars, goed voor Meta en goed voor de wereld.
Onze nieuwste modellen brengen open intelligentie voor iedereen, breiden de contextlengte uit tot 128K, voegen ondersteuning toe voor acht talen en bevatten Llama 3.1 405B - het eerste open source AI-model op grensniveau.
Llama 3.1 405B is een klasse apart, met ongeëvenaarde flexibiliteit, controle en state-of-the-art mogelijkheden die kunnen wedijveren met de beste closed source modellen. Ons nieuwe model zal de gemeenschap in staat stellen om nieuwe workflows te ontsluiten, zoals het genereren van synthetische gegevens en het distilleren van modellen.
We blijven Llama uitbouwen tot een systeem door meer componenten te leveren die met het model werken, waaronder een referentiesysteem. We willen ontwikkelaars de tools geven om hun eigen aangepaste agents en nieuwe soorten agentgedrag te creëren. We versterken dit met nieuwe beveiligings- en veiligheidstools, waaronder Llama Guard 3 en Prompt Guard, om verantwoord te helpen bouwen. We publiceren ook een verzoek om commentaar op de Llama Stack API, een standaardinterface waarvan we hopen dat deze het makkelijker maakt voor projecten van derden om gebruik te maken van Llama-modellen.
Het ecosysteem is klaar voor gebruik met meer dan 25 partners, waaronder AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud en Snowflake die op dag één diensten aanbieden.
Probeer Llama 3.1 405B in de VS uit op WhatsApp en op meta.ai door een uitdagende reken- of codeervraag te stellen.
AANBEVOLEN LECTUUR
Het Lama-ecosysteem op verantwoorde wijze uitbreiden
Het Lama-ecosysteem: Verleden, heden en toekomst
Tot op heden liepen open source grote taalmodellen meestal achter op hun gesloten tegenhangers als het ging om mogelijkheden en prestaties. Nu luiden we een nieuw tijdperk in met open source voorop. We geven Meta Llama 3.1 405B publiekelijk vrij, wat volgens ons 's werelds grootste en meest capabele openlijk beschikbare foundationmodel is. Met meer dan 300 miljoen downloads van alle Llama-versies tot nu toe, zijn we nog maar net begonnen.
Llama 3.1
Llama 3.1 405B is het eerste openlijk beschikbare model dat zich kan meten met de beste AI-modellen als het gaat om state-of-the-art capaciteiten in algemene kennis, bestuurbaarheid, wiskunde, gereedschapgebruik en meertalig vertalen. Met de release van het 405B-model zijn we klaar om innovatie een superboost te geven, met ongekende mogelijkheden voor groei en exploratie. Wij geloven dat de nieuwste generatie van Llama nieuwe toepassingen en modelleerparadigma's zal ontketenen, waaronder het genereren van synthetische gegevens om de verbetering en training van kleinere modellen mogelijk te maken, evenals modeldistillatie-een mogelijkheid die nog nooit op deze schaal in open source is bereikt.
Als onderdeel van deze nieuwste release introduceren we verbeterde versies van de 8B en 70B modellen. Deze zijn meertalig en hebben een aanzienlijk langere contextlengte van 128K, state-of-the-art toolgebruik en over het algemeen sterkere redeneermogelijkheden. Hierdoor kunnen onze nieuwste modellen geavanceerde gebruikssituaties ondersteunen, zoals samenvattingen van lange teksten, meertalige conversatieagenten en codeerassistenten. We hebben ook onze licentie aangepast, zodat ontwikkelaars de output van Llama-modellen, inclusief de 405B, kunnen gebruiken om andere modellen te verbeteren. Trouw aan onze toewijding aan open source, stellen we vanaf vandaag deze modellen beschikbaar aan de gemeenschap om te downloaden op llama.meta.com en Hugging Face en beschikbaar voor onmiddellijke ontwikkeling op ons brede ecosysteem van partnerplatforms.
Model evaluaties
Voor deze release hebben we de prestaties geëvalueerd op meer dan 150 benchmark datasets die een breed scala aan talen omvatten. Daarnaast hebben we uitgebreide menselijke evaluaties uitgevoerd om Llama 3.1 te vergelijken met concurrerende modellen in echte situaties. Uit onze experimentele evaluatie blijkt dat ons vlaggenschipmodel kan concurreren met toonaangevende foundationmodellen in een reeks taken, waaronder GPT-4, GPT-4o en Claude 3.5 Sonnet. Daarnaast zijn onze kleinere modellen concurrerend met gesloten en open modellen die een vergelijkbaar aantal parameters hebben.
Modelarchitectuur
Als ons grootste model tot nu toe was het trainen van Llama 3.1 405B op meer dan 15 biljoen tokens een grote uitdaging. Om trainingsruns op deze schaal mogelijk te maken en de resultaten die we hebben behaald in een redelijke hoeveelheid tijd te behalen, hebben we onze volledige trainingsstack aanzienlijk geoptimaliseerd en onze modeltraining naar meer dan 16 duizend H100 GPU's geduwd, waardoor de 405B het eerste Llama-model is dat op deze schaal is getraind.
Om dit aan te pakken, hebben we ontwerpkeuzes gemaakt die gericht zijn op het schaalbaar en eenvoudig houden van het modelontwikkelingsproces.
We kozen voor een standaard decoder-only transformatormodelarchitectuur met kleine aanpassingen in plaats van een mix-van-experts-model om de trainingsstabiliteit te maximaliseren.
We gebruikten een iteratieve post-training procedure, waarbij elke ronde gebruik maakt van gecontroleerde fijnafstemming en directe voorkeursoptimalisatie. Hierdoor konden we voor elke ronde synthetische gegevens van de hoogste kwaliteit creëren en de prestaties van elk vermogen verbeteren.
Vergeleken met eerdere versies van Llama hebben we zowel de kwantiteit als de kwaliteit van de gegevens die we gebruiken voor pre- en post-training verbeterd. Deze verbeteringen omvatten de ontwikkeling van meer zorgvuldige pijplijnen voor pre-processing en curatie voor pre-training data, en de ontwikkeling van meer rigoureuze kwaliteitsborging en filterbenaderingen voor post-training data.
Zoals verwacht door de schaalwetten voor taalmodellen, presteert ons nieuwe vlaggenschipmodel beter dan kleinere modellen die met dezelfde procedure zijn getraind. We gebruikten het 405B parametermodel ook om de kwaliteit van onze kleinere modellen na de training te verbeteren.
Om grootschalige productie-inferentie voor een model op de schaal van de 405B te ondersteunen, kwantiseerden we onze modellen van 16-bits (BF16) naar 8-bits (FP8) numerieke waarden, waardoor de benodigde rekenkracht effectief werd verlaagd en het model op een enkele servernode kon draaien.
Verfijning van instructies en chat
Met Llama 3.1 405B streefden we naar het verbeteren van de hulpvaardigheid, kwaliteit en gedetailleerde instructie-volgmogelijkheden van het model als reactie op instructies van gebruikers, terwijl we tegelijkertijd een hoog veiligheidsniveau wilden waarborgen. Onze grootste uitdagingen waren het ondersteunen van meer mogelijkheden, het 128K contextvenster en grotere modelgroottes.
In post-training produceren we definitieve chatmodellen door verschillende uitlijningsronden uit te voeren bovenop het voorgetrainde model. Elke ronde omvat Supervised Fine-Tuning (SFT), Rejection Sampling (RS) en Direct Preference Optimization (DPO). We maken gebruik van synthetische gegevens om de overgrote meerderheid van onze SFT-voorbeelden te produceren, waarbij we meerdere keren itereren om synthetische gegevens van steeds hogere kwaliteit te produceren voor alle mogelijkheden. Daarnaast investeren we in meerdere gegevensverwerkingstechnieken om deze synthetische gegevens te filteren op de hoogste kwaliteit. Dit stelt ons in staat om de hoeveelheid fijnafstemmingsgegevens over alle mogelijkheden te schalen.
We balanceren de gegevens zorgvuldig om een model van hoge kwaliteit te produceren voor alle mogelijkheden. Wij behouden bijvoorbeeld de kwaliteit van ons model bij benchmarks met een korte context, zelfs wanneer we uitbreiden naar 128K context. Op dezelfde manier blijft ons model maximaal bruikbare antwoorden geven, zelfs als we veiligheidsbeperkingen toevoegen.
Het Lama-systeem
Het was altijd de bedoeling dat Llama-modellen zouden werken als onderdeel van een overkoepelend systeem dat verschillende componenten kan orkestreren, inclusief het aanroepen van externe hulpmiddelen. Onze visie is om verder te gaan dan de basismodellen en ontwikkelaars toegang te geven tot een breder systeem dat hen de flexibiliteit geeft om aangepaste aanbiedingen te ontwerpen en te creëren die aansluiten bij hun visie. Deze denkwijze begon vorig jaar, toen we voor het eerst de integratie van componenten buiten de kern van LLM introduceerden.
Als onderdeel van onze voortdurende inspanningen om AI op een verantwoorde manier buiten de modellaag te ontwikkelen en om anderen te helpen hetzelfde te doen, brengen we een volledig referentiesysteem uit dat verschillende voorbeeldtoepassingen bevat en nieuwe componenten bevat zoals Llama Guard 3, een meertalig veiligheidsmodel en Prompt Guard, een promptinjectiefilter. Deze voorbeeldapplicaties zijn open source en kunnen door de gemeenschap verder ontwikkeld worden.
De implementatie van componenten in deze Llama System visie is nog steeds gefragmenteerd. Daarom zijn we gaan samenwerken met de industrie, startups en de bredere gemeenschap om de interfaces van deze componenten beter te definiëren. Om dit te ondersteunen, publiceren we een verzoek om commentaar op GitHub voor wat we de "Llama Stack" noemen Llama Stack is een verzameling gestandaardiseerde en opiniërende interfaces voor het bouwen van canonieke toolchaincomponenten (fijnafstemming, synthetische gegevensgeneratie) en agentapplicaties. We hopen dat deze in het hele ecosysteem worden overgenomen, wat de interoperabiliteit zou moeten vergemakkelijken.
We verwelkomen feedback en manieren om het voorstel te verbeteren. We zijn enthousiast om het ecosysteem rond Llama te laten groeien en barrières voor ontwikkelaars en platformaanbieders te verlagen.
Openheid stimuleert innovatie
In tegenstelling tot gesloten modellen, kunnen de modelgewichten van Llama gedownload worden. Ontwikkelaars kunnen de modellen volledig aanpassen aan hun behoeften en toepassingen, trainen op nieuwe datasets en extra fine-tuning uitvoeren. Hierdoor kunnen de ontwikkelaarsgemeenschap en de wereld de kracht van generatieve AI beter benutten. Ontwikkelaars kunnen hun modellen volledig aanpassen aan hun toepassingen en in elke omgeving draaien, inclusief on prem, in de cloud of zelfs lokaal op een laptop - en dat alles zonder gegevens te delen met Meta.
Hoewel velen zullen beweren dat gesloten modellen kosteneffectiever zijn, bieden Llama-modellen enkele van de laagste kosten per token in de branche, volgens tests van Artificial Analysis. En zoals Mark Zuckerberg opmerkte, zal open source ervoor zorgen dat meer mensen over de hele wereld toegang hebben tot de voordelen en mogelijkheden van AI, dat de macht niet geconcentreerd is in de handen van een klein aantal mensen, en dat de technologie gelijkmatiger en veiliger kan worden ingezet in de hele samenleving. Daarom blijven we stappen zetten om ervoor te zorgen dat AI met open toegang de industriestandaard wordt.
We hebben de gemeenschap verbazingwekkende dingen zien bouwen met eerdere Llama-modellen, waaronder een AI-studiebuddy die met Llama is gebouwd en wordt ingezet in WhatsApp en Messenger, een LLM op maat voor de medische sector die is ontworpen om te helpen bij klinische besluitvorming, en een startup zonder winstoogmerk in de gezondheidszorg in Brazilië die het voor de gezondheidszorg gemakkelijker maakt om de informatie van patiënten over hun ziekenhuisopname te organiseren en te communiceren, en dat alles op een gegevensveilige manier. We kunnen niet wachten om te zien wat zij bouwen met onze nieuwste modellen dankzij de kracht van open source.
Bouwen met Llama 3.1 405B
Voor de gemiddelde ontwikkelaar is het een uitdaging om een model op de schaal van de 405B te gebruiken. Hoewel het een ongelooflijk krachtig model is, erkennen we dat het aanzienlijke rekenkracht en expertise vereist om mee te werken. We hebben met de community gesproken, en we realiseren ons dat er zoveel meer komt kijken bij het ontwikkelen van generatieve AI dan alleen het opvragen van modellen. We willen iedereen in staat stellen om het meeste uit de 405B te halen, inclusief:
Real-time en batch inferentie
Fijnafstemming onder toezicht
Evaluatie van uw model voor uw specifieke toepassing
Voortdurende pre-training
Retrieval-Augmented Generation (RAG)
Functie aanroepen
Synthetische gegevens genereren
Dit is waar het Llama ecosysteem kan helpen. Op dag één kunnen ontwikkelaars profiteren van alle geavanceerde mogelijkheden van het 405B-model en direct beginnen met bouwen. Ontwikkelaars kunnen ook geavanceerde workflows verkennen, zoals het gebruiksvriendelijk genereren van synthetische gegevens, kant-en-klare aanwijzingen volgen voor modeldistillatie en naadloze RAG mogelijk maken met oplossingen van partners, waaronder AWS, NVIDIA en Databricks. Daarnaast heeft Groq inference met lage latentie geoptimaliseerd voor cloudimplementaties, en Dell heeft vergelijkbare optimalisaties bereikt voor on-prem systemen.
We hebben samengewerkt met belangrijke gemeenschapsprojecten zoals vLLM, TensorRT en PyTorch om ondersteuning in te bouwen vanaf dag één, zodat de gemeenschap klaar is voor productie-implementatie.
We hopen dat onze uitgave van de 405B ook een stimulans zal zijn voor innovatie binnen de bredere gemeenschap om inferentie en fijnafstemming van modellen van deze schaal gemakkelijker te maken en de volgende golf van onderzoek naar modeldistillatie mogelijk te maken.
Probeer de Llama 3.1 collectie van modellen vandaag nog uit
We kunnen niet wachten om te zien wat de gemeenschap met dit werk doet. Er is zoveel potentieel voor het bouwen van nuttige nieuwe ervaringen met behulp van de meertaligheid en grotere contextlengte. Met de Llama Stack en nieuwe veiligheidstools kijken we ernaar uit om op een verantwoorde manier samen met de open source gemeenschap te blijven bouwen. Voordat we een model uitbrengen, werken we eraan om potentiële risico's te identificeren, evalueren en beperken door middel van verschillende maatregelen, waaronder risico-ontdekkingsoefeningen voorafgaand aan de uitrol door middel van red teaming en het verfijnen van de veiligheid. We voeren bijvoorbeeld uitgebreide red teaming uit met zowel externe als interne experts om de modellen te stresstesten en onverwachte manieren te vinden waarop ze gebruikt kunnen worden. (Lees meer over hoe we onze Llama 3.1 verzameling modellen op een verantwoorde manier opschalen in dit blogbericht)
Hoewel dit ons grootste model tot nu toe is, geloven we dat er nog genoeg nieuw terrein te verkennen valt in de toekomst, waaronder apparaatvriendelijkere formaten, extra modaliteiten en meer investeringen in de laag van het agentplatform. Zoals altijd kijken we uit naar alle geweldige producten en ervaringen die de community met deze modellen zal bouwen.
Dit werk werd ondersteund door onze partners in de hele AI-gemeenschap. We willen graag bedanken en erkennen (in alfabetische volgorde): Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel, Kaggle, Microsoft Azure, NVIDIA, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI, en vLLM project ontwikkeld in Sky Computing Lab op UC Berkeley.

