Bio-ingenieursonderzoekers van UCLA creëren zelfaangedreven patch die met behulp van machinaal leren keelspierbewegingen van stille spraak vertaalt naar gesproken spraak
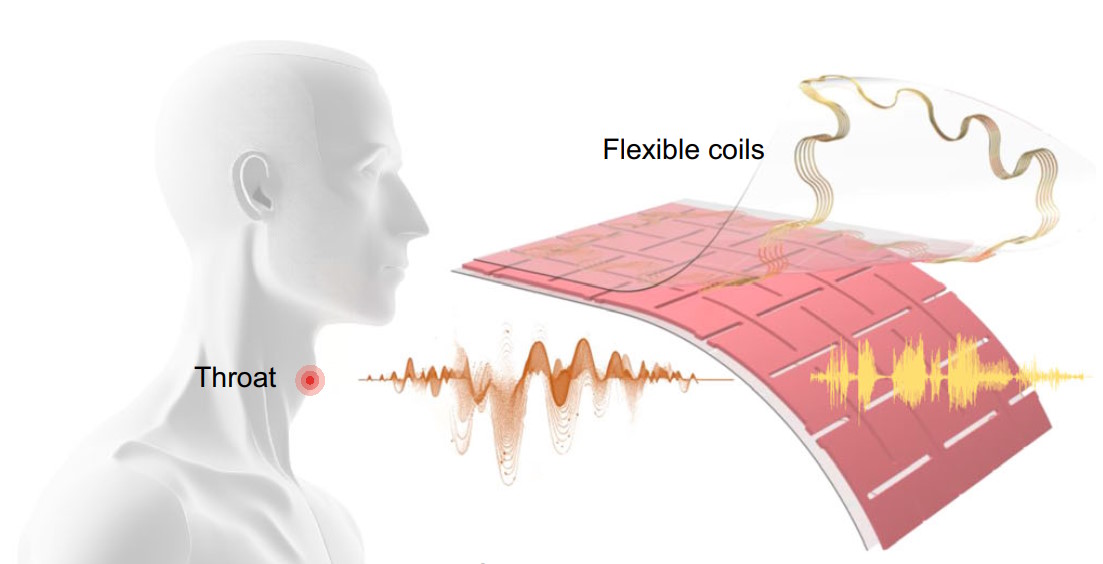
Een groep bio-ingenieursonderzoekers aan de UCLA heeft een flexibele, zelfaangedreven patch gemaakt die bewegingen van de strottenhoofdspieren op het oppervlak van de nek tijdens stille spraak vertaalt in gesproken spraak met behulp van machinaal leren. Deze draagbare patch stelt mensen die anders stom zijn of niet goed kunnen spreken door een stemplooiverwonding, ziekte of aandoening in staat om te spreken met behulp van het voice patch-systeem.
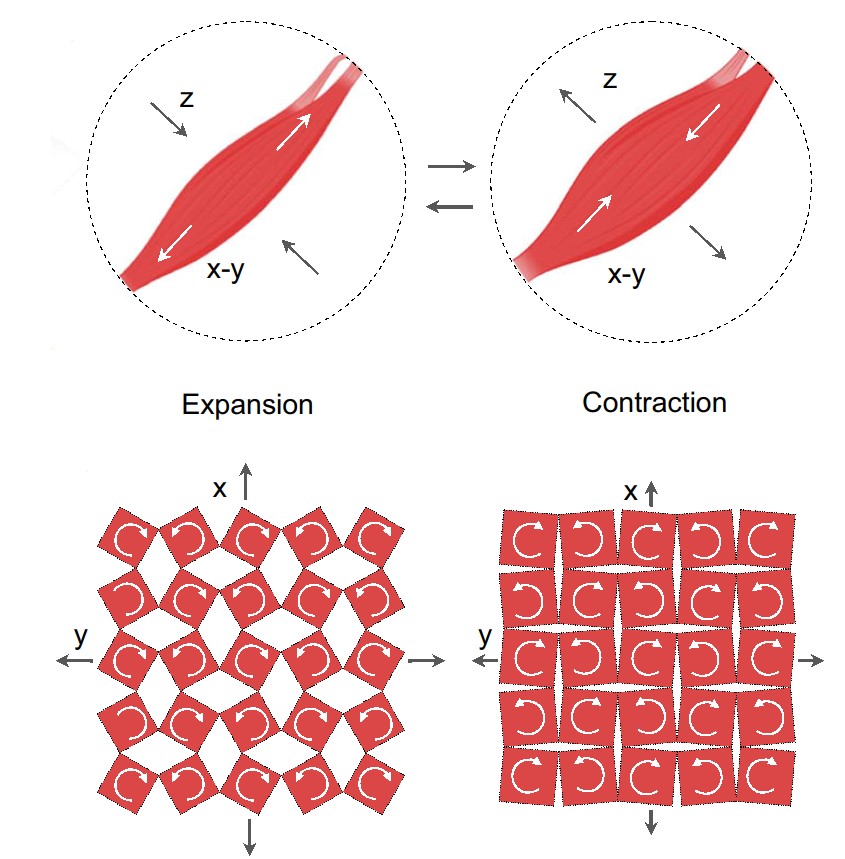
De menselijke stem wordt gecreëerd tijdens het uitademen van lucht door de keel en gemoduleerd door de vele aanwezige strottenhoofdspieren. De strottenhoofdspieren moeten allemaal gecoördineerd bewegen om spraak te produceren, en de bewegingen op het oppervlak van de nek zijn een weerspiegeling van de bewegingen in de keel.
Specifiek is het strottenhoofd het belangrijkst, omdat het de stembandspieren bevat die van vorm veranderen terwijl ze verschillende geluiden voortbrengen. Keelontsteking en overmatig gebruik van de stembanden (schreeuwen, zingen of roepen) zijn vaak voorkomende redenen waarom iemand niet kan spreken omdat de belangrijkste spieren niet goed bewegen om geluid te maken. Maar zelfs als de stembanden niet goed werken, bewegen andere strottenhoofdspieren nog steeds in een poging om te spreken.
De onderzoekers creëerden een zelfklevende pleister die de beweging van de keelspieren kan waarnemen. De patch heeft buitenlagen van polydimethylsiloxaan (PDMS) met daartussen twee lagen koperen spoelen die dienen als de magnetische inductielagen (MI), die gescheiden worden door een enkele laag PDMS en magneten die dienen als de magnetomechanische koppelingslaag (MC). De MC-laag heeft veel insnijdingen zodat deze gemakkelijker kan uitzetten en samentrekken wanneer de keelspieren buigen.
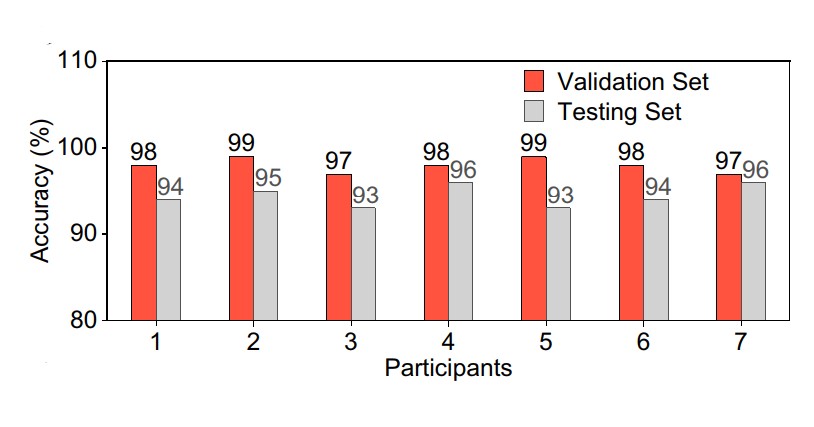
Wanneer een persoon probeert te spreken terwijl hij de 7,2 gram wegende patch draagt, bewegen de spieren en buigt de patch, waardoor er een klein elektrisch signaal wordt gegenereerd dat door de sensormodule wordt opgepikt. Het signaal wordt verwerkt en vervolgens doorgegeven aan de machine-leermodule die het signaal analyseert en interpreteert wat de spreker probeert te zeggen aan de hand van een set van vijf zinnen die gebruikt zijn om het systeem te trainen. Binnen 40 ms spreekt de computer de bedoelde zin uit met een nauwkeurigheid van 94,68 procent.
Het systeem moet getraind worden op een veel breder scala aan woorden en zinnen voordat de voice wearable technologie gewone spraak kan uitspreken, dus lezers die doofstom zijn zouden een boek over morsecode of gebarentaal nuttig kunnen vinden terwijl ze op de patch wachten.