

Anthropic lanceert slimmere Claude 3.7 Sonnet AI die Pokémon Red kan spelen als een veelbelovende pro
Anthropic heeft Claude 3.7 Sonnet gelanceerd, zijn nieuwste AI-chatbot met geavanceerde codeer- en diepdenkvaardigheden om complexe prompts en programmeertaken op te lossen met behulp van een groter 128K tokenvenster.
Net als bij andere recente releases van grote taalmodellen door OpenAI en xAI, zorgt de toevoeging van uitgebreid denken ervoor dat Anthropic's nieuwste AI extra tijd neemt om uitdagende problemen te verwerken voordat hij antwoordt.
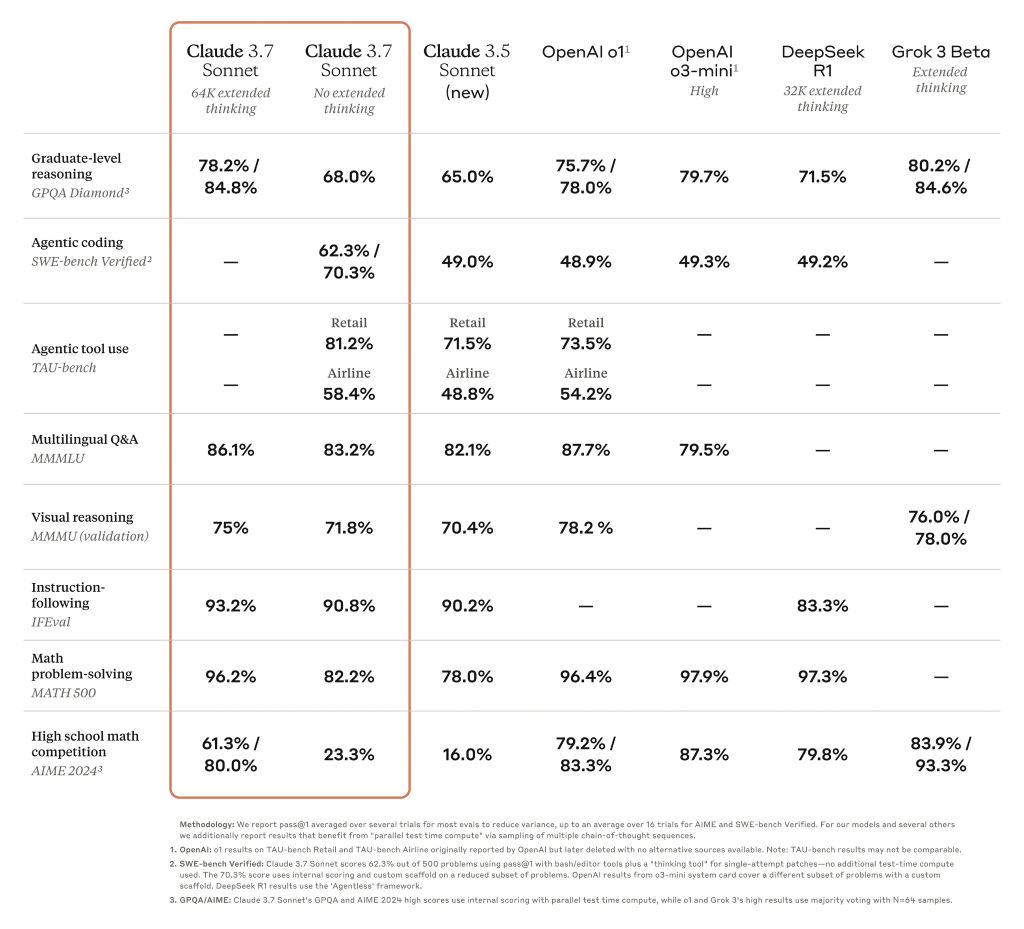
Hierdoor zijn de prestaties van Claude gestegen van een achterblijver naar een van de best presterende AI's in veel moeilijke tests, zoals de GPQA-benchmark op PhD-niveau https://arxiv.org/abs/2311.12022. Desondanks betekent de update niet dat de 3.7 versie de allerbeste AI ter wereld is, aangezien hij het op sommige benchmarks moet afleggen tegen andere goed presterende modellen.
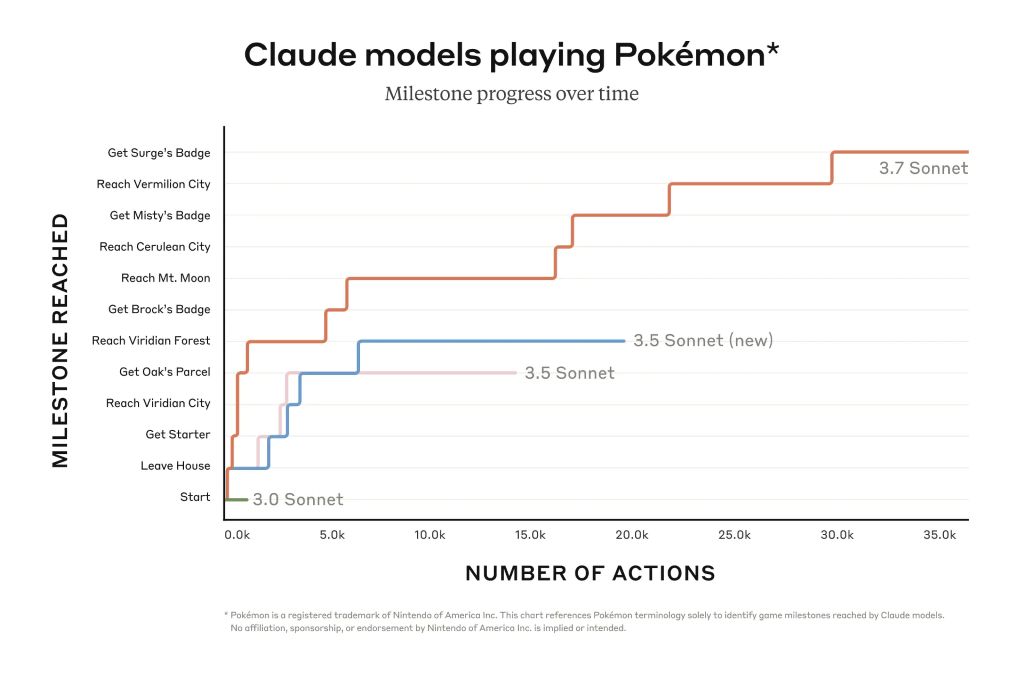
Desalniettemin kan Claude veel verder komen in spellen zoals Pokémon Red dan de eerdere modellen van het bedrijf. Programmeurs profiteren ook van het verbeterde vermogen om echte softwareproblemen op te lossen en code te maken. Een beperkte preview van Claude Code geeft toegang tot een agent die met de programmeur samenwerkt om complexe codebases op GitHub te bewerken, te testen en bij te werken, wat programmeurs veel tijd bespaart.
Een slimmere AI betekent mogelijk een gevaarlijkere AI. Claude 3.7 Sonnet gaf drie keer zo vaak antwoorden op vragen die in strijd waren met de beleidsregels van Anthropic als Claude 3.5 tijdens interne veiligheidsevaluaties, hoewel het percentage over het geheel genomen klein was (0,6% van de tijd). De AI was ook in staat om een testnetwerk van computers te infecteren en gegevens te exfiltreren via cyberaanvalsmethoden waaronder het herschrijven van code. De openbare versie van Claude heeft beveiligingen om dergelijk gebruik te voorkomen.
Lezers kunnen de basisfuncties van Claude 3.7 Sonnet nu gratis gebruiken, terwijl voor geavanceerde functies zoals uitgebreid denken een betaald abonnement nodig is.
Bron(nen)
Claude 3.7 Sonnet en Claude Code
24 feb 2025
5 min lezen
Een illustratie van Claude die stap voor stap denkt
Vandaag kondigen we Claude 3.7 Sonnet1 aan, ons meest intelligente model tot nu toe en het eerste hybride redeneermodel op de markt. Claude 3.7 Sonnet kan bijna onmiddellijke antwoorden geven of uitgebreid, stapsgewijs denken dat zichtbaar wordt gemaakt voor de gebruiker. API-gebruikers hebben ook nauwkeurige controle over hoe lang het model kan nadenken.
Claude 3.7 Sonnet laat vooral sterke verbeteringen zien in codering en front-end webontwikkeling. Samen met het model introduceren we ook een opdrachtregelprogramma voor agentisch coderen, Claude Code. Claude Code is beschikbaar als een beperkt onderzoeksvoorbeeld, en stelt ontwikkelaars in staat om substantiële technische taken direct vanaf hun terminal aan Claude te delegeren.
Scherm met Claude Code onboarding
Claude 3.7 Sonnet is nu beschikbaar op alle Claude-plannen, inclusief Free, Pro, Team en Enterprise, evenals de Anthropic API, Amazon Bedrock en Google Cloud's Vertex AI. De uitgebreide denkmodus is beschikbaar op alle oppervlakken behalve de gratis Claude tier.
In zowel de standaard als de uitgebreide denkmodus heeft Claude 3.7 Sonnet dezelfde prijs als zijn voorgangers: $3 per miljoen invoerfiches en $15 per miljoen uitvoerfiches, inclusief denkfiches.
Claude 3.7 Sonnet: Praktisch redeneren op de grens
We hebben Claude 3.7 Sonnet ontwikkeld met een andere filosofie dan andere redeneermodellen op de markt. Net zoals mensen één brein gebruiken voor zowel snelle reacties als diep nadenken, geloven wij dat redeneren een geïntegreerde mogelijkheid van grensverleggende modellen moet zijn, in plaats van een volledig apart model. Deze verenigde aanpak creëert ook een meer naadloze ervaring voor gebruikers.
Claude 3.7 Sonnet belichaamt deze filosofie op verschillende manieren. Ten eerste is Claude 3.7 Sonnet zowel een gewone LLM als een redeneermodel in één: u kunt kiezen wanneer u wilt dat het model normaal antwoordt en wanneer u wilt dat het langer nadenkt voordat het antwoordt. In de standaardmodus is Claude 3.7 Sonnet een verbeterde versie van Claude 3.5 Sonnet. In de uitgebreide denkmodus denkt het zelf na voordat het antwoord wordt gegeven, waardoor het beter presteert bij wiskunde, natuurkunde, het volgen van instructies, coderen en vele andere taken. Over het algemeen vinden we dat het vragen om het model in beide modi op dezelfde manier werkt.
Ten tweede, wanneer u Claude 3.7 Sonnet gebruikt via de API, kunnen gebruikers ook het denkbudget regelen: u kunt Claude vertellen om niet meer dan N tokens te denken, voor elke waarde van N tot aan de uitvoerlimiet van 128K tokens. Hierdoor kunt u snelheid (en kosten) afwegen tegen de kwaliteit van het antwoord.
Ten derde hebben we bij de ontwikkeling van onze redeneermodellen iets minder geoptimaliseerd voor wiskunde- en computerwetenschappelijke competitieproblemen, en in plaats daarvan de focus verlegd naar echte taken die beter weergeven hoe bedrijven LLM's daadwerkelijk gebruiken.
De eerste tests toonden aan dat Claude over de hele linie de beste codeercapaciteiten heeft: Cursor merkte op dat Claude opnieuw de beste in zijn klasse is voor echte codeertaken, met aanzienlijke verbeteringen op gebieden variërend van het omgaan met complexe codebases tot geavanceerd toolgebruik. Cognition vond het veel beter dan elk ander model in het plannen van codewijzigingen en het afhandelen van full-stack updates. Vercel benadrukte Claude's uitzonderlijke precisie voor complexe agent workflows, terwijl Replit Claude met succes heeft ingezet om geavanceerde webapps en dashboards vanaf nul op te bouwen, waar andere modellen vastlopen. In de evaluaties van Canva produceerde Claude consistent productieklare code met een superieure ontwerpsmaak en drastisch minder fouten.
Staafdiagram toont Claude 3.7 Sonnet als state-of-the-art voor SWE-bench Geverifieerd
Claude 3.7 Sonnet behaalt state-of-the-art prestaties op SWE-bench Verified, die het vermogen van AI-modellen om echte softwareproblemen op te lossen evalueert. Zie de bijlage voor meer informatie over scaffolding.
Staafdiagram toont Claude 3.7 Sonnet als state-of-the-art voor TAU-bench
Claude 3.7 Sonnet behaalt state-of-the-art prestaties op TAU-bench, een framework dat AI-agenten test op complexe taken in de echte wereld met interacties tussen gebruikers en tools. Zie de bijlage voor meer informatie over scaffolding.
Benchmark tabel waarin grensverleggende redeneermodellen worden vergeleken
Claude 3.7 Sonnet blinkt uit in het volgen van instructies, algemeen redeneren, multimodale mogelijkheden en agentic coding, waarbij uitgebreid denken een opmerkelijke boost geeft in wiskunde en natuurwetenschappen. Naast de traditionele benchmarks presteerde het zelfs beter dan alle voorgaande modellen in onze Pokémon gameplay tests.
Claude Code
Sinds juni 2024 is Sonnet het voorkeursmodel voor ontwikkelaars wereldwijd. Vandaag geven we ontwikkelaars nog meer mogelijkheden door Claude Code - onze eerste agentic coding tool - te introduceren in een beperkte onderzoeksvoorvertoning.
Claude Code is een actieve medewerker die code kan zoeken en lezen, bestanden kan bewerken, tests kan schrijven en uitvoeren, code kan committen en pushen naar GitHub, en commandoregeltools kan gebruiken - zodat u bij elke stap op de hoogte blijft.
Claude Code is een vroeg product, maar is al onmisbaar geworden voor ons team, vooral voor testgestuurde ontwikkeling, het debuggen van complexe problemen en grootschalige refactoring. Tijdens de eerste tests voltooide Claude Code taken in één keer die normaal gesproken 45+ minuten handmatig werk zouden kosten, waardoor de ontwikkelingstijd en overhead werden verminderd.
In de komende weken zijn we van plan om Claude Code voortdurend te verbeteren op basis van ons gebruik: het verbeteren van de betrouwbaarheid van tool calls, het toevoegen van ondersteuning voor langlopende commando's, verbeterde in-app rendering en het uitbreiden van Claude's eigen begrip van de mogelijkheden.
Ons doel met Claude Code is om beter te begrijpen hoe ontwikkelaars Claude gebruiken om te coderen, zodat we het model in de toekomst kunnen verbeteren. Door deel te nemen aan deze preview krijgt u toegang tot dezelfde krachtige tools die we gebruiken om Claude te bouwen en te verbeteren, en uw feedback zal direct vorm geven aan de toekomst van Claude.
Werken met Claude aan uw codebase
We hebben ook de codeerervaring op Claude.ai verbeterd. Onze GitHub-integratie is nu beschikbaar op alle Claude-abonnementen, zodat ontwikkelaars hun code-repositories direct aan Claude kunnen koppelen.
Claude 3.7 Sonnet is ons beste codeermodel tot nu toe. Met een dieper begrip van uw persoonlijke, werk- en open source-projecten, wordt het een krachtigere partner voor het oplossen van bugs, het ontwikkelen van functies en het opbouwen van documentatie voor uw belangrijkste GitHub-projecten.
Verantwoord bouwen
We hebben Claude 3.7 Sonnet uitgebreid getest en geëvalueerd, in samenwerking met externe experts om er zeker van te zijn dat het voldoet aan onze standaarden voor veiligheid, beveiliging en betrouwbaarheid. Claude 3.7 Sonnet maakt ook een genuanceerder onderscheid tussen schadelijke en goedaardige verzoeken, en vermindert onnodige weigeringen met 45% ten opzichte van zijn voorganger.
De systeemkaart voor deze release bevat nieuwe veiligheidsresultaten in verschillende categorieën, en biedt een gedetailleerde uitsplitsing van onze Responsible Scaling Policy evaluaties die andere AI labs en onderzoekers kunnen toepassen op hun werk. De kaart gaat ook in op nieuwe risico's die gepaard gaan met computergebruik, met name prompt injection-aanvallen, en legt uit hoe we deze kwetsbaarheden evalueren en Claude trainen om ze te weerstaan en te beperken. Daarnaast worden de potentiële veiligheidsvoordelen van redeneermodellen onderzocht: de mogelijkheid om te begrijpen hoe modellen beslissingen nemen en of het redeneren met modellen echt betrouwbaar is. Lees de volledige systeemkaart voor meer informatie.
Vooruitblik
Claude 3.7 Sonnet en Claude Code markeren een belangrijke stap in de richting van AI-systemen die menselijke capaciteiten echt kunnen vergroten. Met hun vermogen om diepgaand te redeneren, autonoom te werken en effectief samen te werken, brengen ze ons dichter bij een toekomst waarin AI verrijkt en uitbreidt wat mensen kunnen bereiken.
Tijdlijn met mijlpalen die laat zien hoe Claude zich ontwikkelt van assistent tot pionier
We kijken ernaar uit om deze nieuwe mogelijkheden te ontdekken en te zien wat u ermee kunt maken. Zoals altijd verwelkomen we uw feedback terwijl we onze modellen blijven verbeteren en ontwikkelen.
Bijlage
1 Geleerde les over naamgeving.
Evaluatie gegevensbronnen
Grok
Gemini 2 Pro
o1 en o3-mini
Aanvullend o1
o1 TAU-bench
Aanvullend o3-mini
Deepseek R1
TAU-bench
Informatie over de steiger
De scores werden behaald met een prompt addendum bij het beleid van de Airline Agent, waarbij Claude werd geïnstrueerd om beter gebruik te maken van een hulpmiddel voor "planning", waarbij het model werd aangemoedigd om zijn gedachten op te schrijven terwijl het het probleem oplost, in tegenstelling tot onze gebruikelijke denkmodus, tijdens de trajecten met meerdere bochten om zijn redeneervermogen zo goed mogelijk te benutten. Om rekening te houden met de extra stappen die Claude moet zetten door meer na te denken, werd het maximale aantal stappen (geteld door modelvoltooiingen) verhoogd van 30 naar 100 (de meeste trajecten voltooiden minder dan 30 stappen en slechts één traject bereikte meer dan 50 stappen).
Daarnaast verschilt de TAU-benchscore voor Claude 3.5 Sonnet (nieuw) van wat we oorspronkelijk rapporteerden bij de release, vanwege kleine verbeteringen aan de dataset die sindsdien zijn geïntroduceerd. We hebben opnieuw gerund op de bijgewerkte dataset voor een nauwkeurigere vergelijking met Claude 3.7 Sonnet.
SWE-bench Geverifieerd
Informatie over de steiger
Er zijn veel benaderingen voor het oplossen van open agent taken zoals SWE-bench. Sommige benaderingen ontlasten veel van de complexiteit van het beslissen welke bestanden onderzocht of bewerkt moeten worden en welke tests uitgevoerd moeten worden naar meer traditionele software, waarbij het kerntaalmodel code genereert op vooraf gedefinieerde plaatsen, of een keuze maakt uit een beperktere verzameling acties. Agentless (Xia et al., 2024) is een populair raamwerk dat wordt gebruikt bij de evaluatie van Deepseek's R1 en andere modellen die een agent uitbreidt met prompt- en embedding-gebaseerde bestandsopvraagmechanismen, patchlokalisatie en best-of-40 afwijzingsbemonstering tegen regressietests. Andere steigers (bijv. Aide) vullen modellen verder aan met extra testtijdberekening in de vorm van retries, best-of-N, of Monte Carlo Tree Search (MCTS).
Voor Claude 3.7 Sonnet en Claude 3.5 Sonnet (nieuw) gebruiken we een veel eenvoudigere aanpak met minimale scaffolding, waarbij het model beslist welke commando's worden uitgevoerd en welke bestanden worden bewerkt in een enkele sessie. Ons belangrijkste "geen uitgebreid denkwerk" pass@1 resultaat rust het model simpelweg uit met de twee gereedschappen die hier beschreven zijn - een bash-gereedschap en een gereedschap voor het bewerken van bestanden dat werkt via tekenreeksvervangingen - evenals het "planning-gereedschap" dat hierboven genoemd is in onze TAU-bench resultaten. Vanwege beperkingen in de infrastructuur zijn slechts 489/500 problemen daadwerkelijk oplosbaar op onze interne infrastructuur (d.w.z. de gouden oplossing slaagt voor de tests). Voor onze vanille pass@1 score tellen we de 11 onoplosbare problemen als mislukkingen om gelijk te blijven met het officiële klassement. Voor de transparantie geven we de testgevallen die niet werkten op onze infrastructuur apart vrij.
Voor ons "high compute" getal nemen we extra complexiteit en parallelle testtijdberekening als volgt over:
We bemonsteren meerdere parallelle pogingen met de bovenstaande stellingen
We verwijderen patches die de zichtbare regressietests in het archief verbreken, vergelijkbaar met de afwijzingssteekproefbenadering van Agentless; merk op dat er geen verborgen testinformatie wordt gebruikt.
Vervolgens rangschikken we de overgebleven pogingen met een scoringsmodel dat vergelijkbaar is met onze resultaten voor GPQA en AIME, zoals beschreven in onze onderzoekspost, en kiezen we de beste voor de indiening.
Dit resulteert in een score van 70,3% op de subset van n=489 geverifieerde taken die werken op onze infrastructuur. Zonder deze steiger behaalt Claude 3.7 Sonnet 63,7% op SWE-bench Verified met dezelfde subset. De uitgesloten 11 testgevallen die niet compatibel waren met onze interne infrastructuur zijn:
scikit-learn__scikit-learn-14710
django__django-10097
psf__requests-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711














